
| Version 15 (modified by , 10 years ago) (diff) |
|---|
Overview of Operational Monitoring
This is a working page for the operational monitoring project. It is a draft representing work in progress.
Introduction
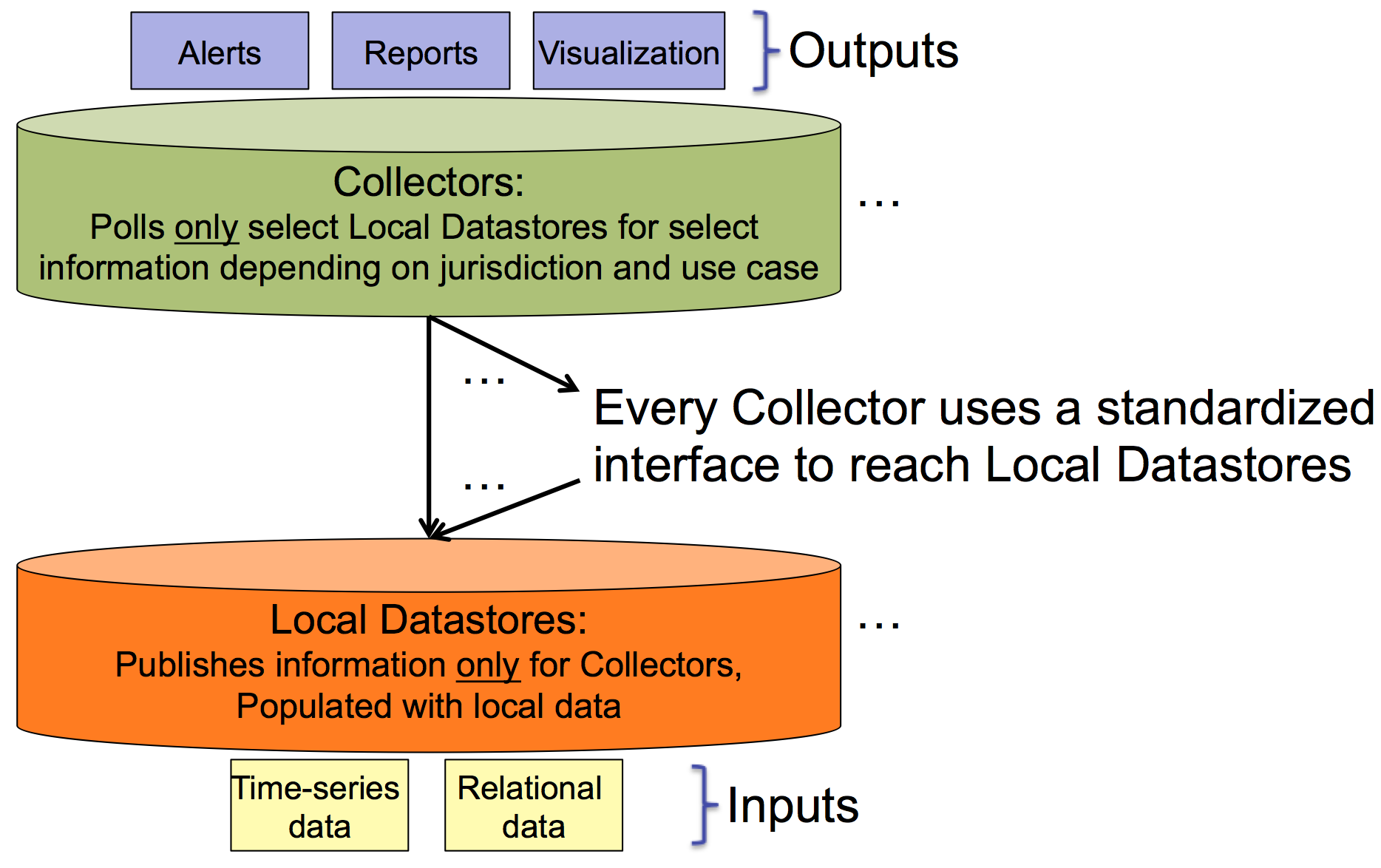
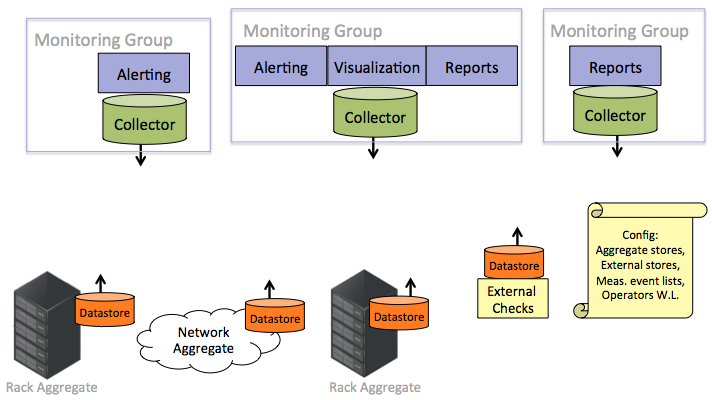
The monitoring architecture is based on the concept of distributing sources of information in a common fashion. The sources of information (relational data or time-series data) is placed into what are called "Local Datastores". These datastores have a common REST polling API for retrieving information. The component that automatically retrieves data from the Local Datastores are called "collectors".
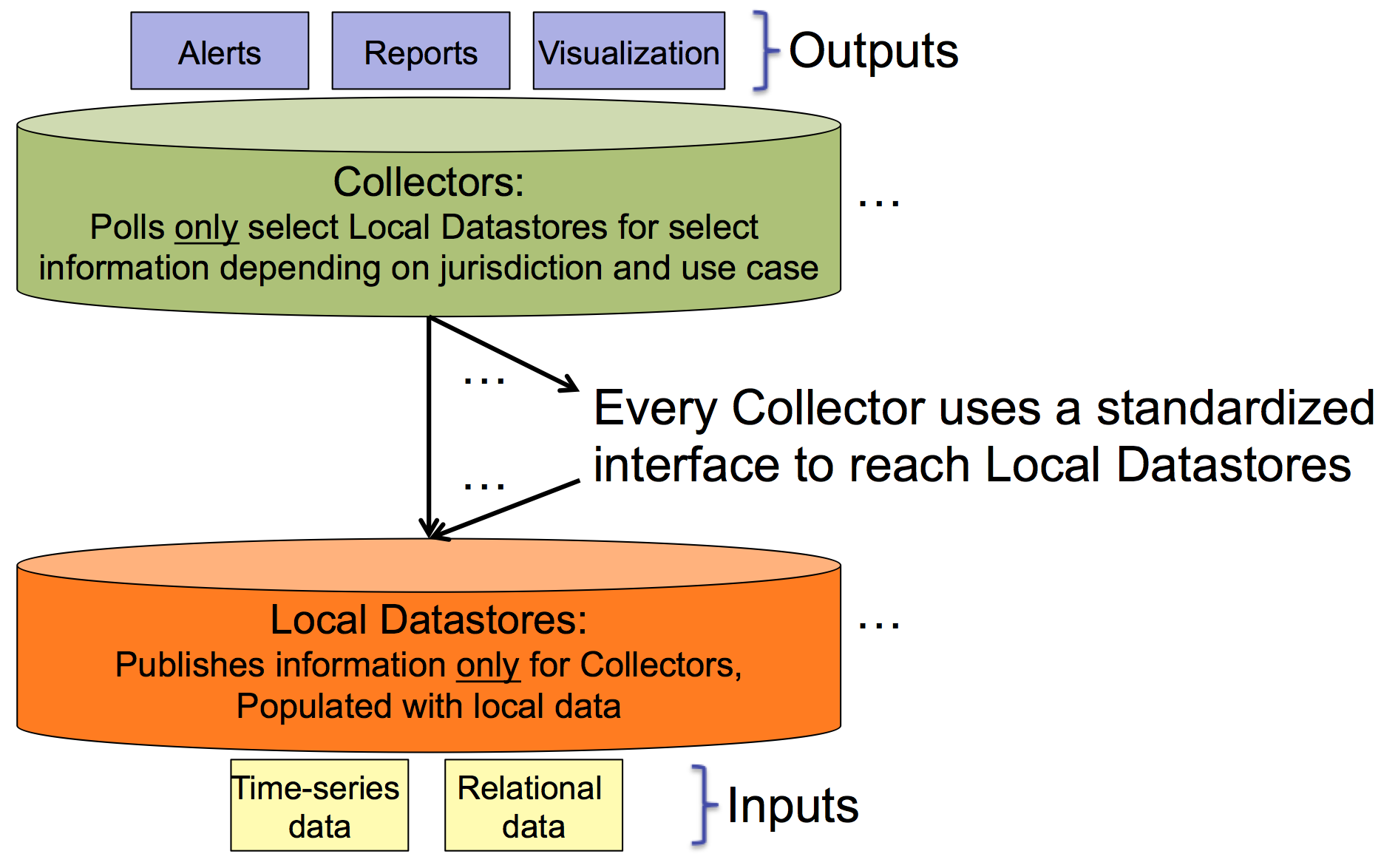 |
A collector can poll a variety of datastores and any subset of data within each datastore. A monitoring application relies on a collector for its data queries, so collectors poll whatever data is necessary to have sufficient data to support the attached monitoring applications (i.e., alerting, reporting, historical analysis, visualization).
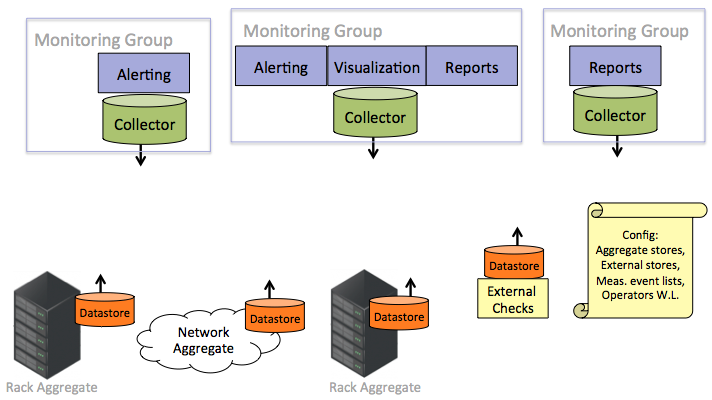 |
Although there are multiple collectors, a single monitoring application uses only a single collector.
Use Cases
Simple Rack Health (use case 3)
Use case description: Track node compute utilization, interface, and health statistics for shared rack nodes, and allow operators to get notifications when they are out of bounds
Use case implementation story: Node statistics are time-series data, and are either collected on the node and pushed to the compute aggregate, or polled from each node by the compute aggregate (doesn't matter for our purposes). Statistics end up in a local database on each rack. Any group of operators that wants to send notifications on these statistics runs a collector, which polls all racks of interest to that group. The collector shares current values with an alerting service, which sends alerts.
 |
Sliver Usage (use case 6)
Use case description: Find out what slivers will be affected by a maintenance or outage of some resource, and get contact information for the owners of those slivers so targeted notifications can be sent
Use case implementation story: Aggregates collect up-to-date information about what slivers exist and what resources they have reserved (including sliver details such as expiration time), and make this information available via a local datastore. GENI trust authorities (e.g. clearinghouses) collect up-to-date information about experimenters and their contact information, and make this information available via a local datastore. Operators who want to be able to get this information run a collector which can query the relevant datastores (since this is an on-demand real-time query, the collector doesn't need to be active all the time, though it may be). The collector data is used to run a report listing affected experimenters and their contact info.
 |
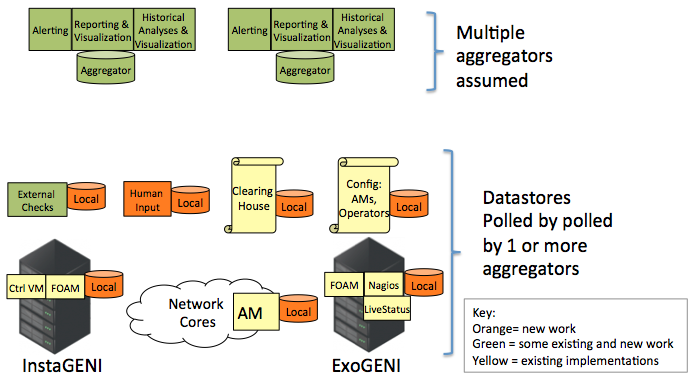
External Checks Datastore for Control and Data Plane Monitoring
 |
Aggregate Datastores for Control and Data Plane Monitoring
 |
Attachments (3)
- monitoring_architecture.png (91.7 KB) - added by 10 years ago.
- local_datastores_collectors.png (181.6 KB) - added by 10 years ago.
- GENI_implementation.png (79.6 KB) - added by 10 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip