
-
Combined GENI - Mozilla Design and Coding Sprint and Hackfest
- Schedule
- Session Leaders
- Agenda / Details
-
Coding Sprint Meeting Summary
- Attendees
- Summary
-
Session Details
- Change Set G: Specifying credential types
- Change Set I2: Return SSH logins in the RSpec
- Change Set K: Use a UUID to uniquely identify slices over time
- Change Set K: Include UUID and email address in slice and user certificates
- Change Set F: Define sliver allocation states and state change methods
- Still to do
Combined GENI - Mozilla Design and Coding Sprint and Hackfest
Join us to hack on the future of GENI ! Whether you're a software developer, an experimenter, or just plain interested, come work side-by-side on GENI related ideas and problems.
Schedule
Coding sprint: Thursday, 1:30 pm - 4:30pm
Hackfest: Thursday, 1:30 pm - 9:00 pm
Session Leaders
Sarah Edwards, Aaron Helsinger, and Niky Riga, GENI Project Office
Allen Gunn, Ben Moskowitz, and Katrin Lepik, Mozilla Foundation
Agenda / Details
Coding Sprint
The coding sprint session provides an opportunity for members of the GENI community to come work side by side with each other. GENI software developers will implement code on a topic selected in advance. Meanwhile, GENI experimenters can setup their own experiments with support from the GPO and other members of the GENI community.
This software development session provides an opportunity for GENI engineers to collaborate in real time on a particular software or documentation issue. The topic will be selected well in advance of the conference, based on need and key party availability. At GEC12, the topic was AM API changes. Particular topics that may be discussed include:
- Change Set G: How do AMs advertise supported credential types?
- Change Set I2: An RSpec extension for listing SSH login keys has been proposed - acceptable? (http://lists.geni.net/pipermail/dev/2012-March/000727.html)
- Change Set K: Tuesday we postponed discussion of having a UUID as a slice ID in slice certificates. Can we agree on that now?
- Change Set K: Can we include both a UUID and email in slice and user certificates?
- Change Set L: Can we consider this proposal to simplify SFA credential privileges?
- Nick has proposed new methods for modifying sliver state and acting on slivers. See http://lists.geni.net/pipermail/dev/2012-March/000721.html
Experimenters with an idea they want to work on are encouraged to come do so in the same room as other GENI experimenters. The GPO will answer questions and provide assistance on configuring the experiment.
It is anticipated that most participants will attend in person, but a telephone and jabber chatroom will be set up for those unable to attend in person.
Hackfest
At this open event, experimenters will have the opportunity to join a design jam facilitated by the Mozilla Foundation. We will strategize and prototype apps that make the power of next-gen networks real and visible for more people.
Through the Ignite Apps Challenge (http://mozillaignite.org), NSF and Mozilla want to help people build things that show off the cool opportunities that GENI presents, especially in national priority areas like health IT, distance education, clean energy and public safety. Over the course of the year, NSF and Mozilla are offering $500k in funding and valuable mentorship to help get these apps off the ground.
Compelling designs from this session could evolve into submissions to the challenge, with seed money and mentorship available to help get them off the ground.
If you're more interested in architectural, design, and documentation issues around GENI, drop in and meet with GPO staff and GENI developers. This session provides an opportunity for both developers and experimenters to work on the things that matter to them.
All GEC attendees are welcome to participate in the combined event. LA-area web developers, designers and civic leaders are also invited to register for free. Invite your developer friends to this open event!
Looking forward to seeing you @ 1-9 pm Thursday March 15th. Nourishment (liquid & otherwise) will be served.
For more information, contact mailto:ignite@mozillafoundation.org.
Coding Sprint Meeting Summary
Attendees
- Rob Ricci (U Utah, ProtoGENI)
- Jon Duerig (U Utah, ProtoGENI)
- Matt Strum (U Utah, Flack)
- Victor Orlikowski (Duke, Orca)
- Prateek Jaipuria (Duke, Orca)
- Jeff Chase (Duke, Orca)
- Nick Bastin (OpenFlow, FOAM)
- Marshall Brinn (GPO)
- Sarah Edwards (GPO)
- Tom Mitchell (GPO)
- Aaron Helsinger (GPO)
- Max Ott (arrived late) (NICTA, OMF)
- Tom Rothe (Ofelia)
- On phone: Gary Wong & Leigh Stoller (U Utah, ProtoGENI)
- others
Summary
At the developers portion of the Coding Sprint session around 20 aggregate and tool developers actively debated several additions to the Aggregate Manager API, agreeing on several key additions to the next version of the AM API, version 3. This session followed the Tuesday afternoon AM API session, allowing for further in depth discussion of key topics. The group met for about 4 hours. The group first discussed some details of proposals adopted during the AM API session, and then discussed additional proposals postponed during the AM API session.
We agreed on multiple changes to be included in AM API version 3. Details of these proposals, and new proposals for AM API version 3 will be discussed on the GENI developers mailing list. Proposals not resolved relatively soon will be discussed for inclusion in a later version of the AM API.
- Change Set G: Advertise and pass credentials with an explicit type and version.
We agreed on how Aggregates will advertise supported credential types, and changed the credentials argument for each AM API method to be a list of structures with an explicit type and version.
- Change Set I2: Return SSH login keys in a standard way.
We agreed to adopt a modified version of the RSpec extension drafted by Jon Duerig (http://lists.geni.net/pipermail/dev/2012-March/000727.html), requiring aggregates that use SSH logins for resources to return valid login names and keys in the manifest RSpec. This extension supplies SSH login information to clients in a standard way.
- Change Set K: Use a UUID to uniquely identify slices over time.
Currently URNs identify slices, but they are not unique over time. This change adds UUIDs to slice identifiers. URNs remain the identifier for slices in AM API calls, and uniquely identify slices for a moment in time. UUID plus URN together uniquely identify slices over time, and can be used for forensics, or for use by authorization modules, such as ABAC. UUIDs alone should not be used to identify slices, but only in conjunction with the URN, which scopes the UUID to the authority which generated the UUID. The UUID essentially may only be used to distinguish between slices with identical URNs.
- Change Set K: Include UUID and email in slice and user certificates.
We adopted the proposal as on the AM API Draft Changes wiki page, to include the UUID and email address in the subjectAltName of both slice and user certificates. As with the use of UUIDs for slices, the user UUID should only be used in conjunction with the user URN. However, user URNs are required to be temporally and globally unique.
- Change Set F: Define sliver allocation states and state change methods.
We discussed Nick Bastin's proposal on sliver states and state change methods (http://lists.geni.net/pipermail/dev/2012-March/000730.html).
We had a long and useful discussion, which resulted in agreement on a variant of his ideas. We agreed to use two kinds of states: allocation states, and operational states. These states apply to each sliver individually. We defined in particular a new allocation state representing resources that have been allocated to a slice without provisioning the resources. This represents a cheap and un-doable resource allocation, such as we previously discussed in the context of tickets. This compares reasonably well to the 'transaction' proposal written up by Gary Wong (http://www.protogeni.net/trac/protogeni/wiki/AM_API_proposals).
We added 2 new methods to the API, and changed the arguments and return value for 4 other methods, to accommodate these new states. In particular, methods return the state of each affected sliver, several methods take a list of sliver URNs or a slice URN. We also changed the semantics of CreateSliver, in a way that touches on operational state. CreateSliver is intended to NOT 'start' resources (the meaning of 'start' is TBD). We have not yet defined the method for starting resources though.
Session Details
Change Set G: Specifying credential types
This discussion follows the adoption at the AM API session of Change Set G, allowing for multiple credential types in the AM API. That change introduces the problem of aggregates advertising what credential types they support, and aggregates understanding what credential types they have been passed.
We agreed that aggregates must advertise what types of credentials they accept so clients know how to gain authorization for API methods.
Aggregates are required to return a new entry in GetVersion:
geni_credential_types = <a list of structs>: [
{
geni_type = <string, case insensitive>,
geni_version = <string containing an integer>,
<others fields optionally. EG A URL for more info, or a schema>
}
]
We agreed that "sfa" slice credentials as defined pre AM API version 3 will have type=geni_sfa and version=2. "sfa" slice credentials as of AM API version 3 will be type=geni_sfa, version=3.
ABAC credentials as of AM API version 3 will be type=geni_abac, version=1.
For example, an aggregate that accepts ABAC credentials, SFA slice credentials that were issued prior to AM API v3, and SFA slice credentials from AM API version 3, would include this in GetVersion:
geni_credential_types = [
{
geni_type = "geni_sfa",
geni_version = "2"
},
{
geni_type="geni_sfa",
geni_version = "3"
},
{
geni_type="geni_abac",
geni_version="1"
}
]
Note that there might be multiple geni_type entries to support multiple versions of SFA credentials.
Note there might also be multiple kinds of ABAC credentials: identity certificates, attribute certificates, references to those certificates, bundles of those certificates. We briefly considered adding a sub_type field or a flag for 'credentials' that are really references to credentials.
Credentials argument
We then discussed whether any changes are required to allow AMs to understand the type of each supplied credential. Several people argued that simple heuristics in the AM would be sufficient, and no changes are needed. But credentials may be in any format, including URLs that reference how to retrieve credentials, hashes to identify pre-cached credentials, etc. As a result credentials may not be easily distinguishable by simply looking at them. Therefore if the API only passed credentials themselves, each AM would have to apply heurisitcs to distinguish them, and those heuristics might differ.
Instead, we agreed that the API will require that credentials be explicitly typed. This change makes methods take in the credentials argument a struct:
credentials = [
{
geni_type = <string>,
geni_version = <string>,
geni_value = <string>,
<others>
}
]
Note that the value may be a credential, a URL, an XLink compliant string, etc. Clients are required to identify the type of each credential they supply. Instead of requiring clients to apply similar heuristics, authorities are required to identify credentials they supply with the same type and version fields. Specifically, ProtoGENI representatives suggested that their slice authorities would issue credentials as these structures in the near future.
Change Set I2: Return SSH logins in the RSpec
At the AM API session, we agreed in principle to Change Set I2, calling for SSH logins to be returned to the experimenter in a standard way. We agreed this should be an RSpec extension for use in manifest RSpecs.
Jon Duerig drafted such an extension, disseminated to the community via email to the dev list.
After a brief discussion, we agreed to adopt this extension. We noted that the extension claims to be general, but in practice is fairly SSH-specific. We noted in particular that the manifest is not a secure way to supply private information like passwords. Instead this extension will primarily be used for transmitting SSH public keys.
The extension adds tags within the existing <services> <login> tag, supplying login names, and 1 or more keys to be used with each login name. Each login name may optionally have a URN, identifying the user.
We adopted the extension with three changes:
- Change 'key' to 'public-key'
- Change 'user' to 'ssh-user'
- Change 'urn' to 'user-urn'
FIXME: Did we agree to change the name of the schema/extension to specify that this is an SSH-specific extension?
Jon Duerig took the action to update this extension.
Change Set K: Use a UUID to uniquely identify slices over time
This change represents a part of Change Set K that was briefly discussed at the AM API session, but on which we could not get agreement. After the AM API session, offline discussions seemed to bring us to consensus. We discussed the reasons we can now agree, and then adopted this change.
Currently URNs identify slices, but they are not unique over time. This change adds UUIDs to slice identifiers. URNs remain the identifier for slices in AM API calls, and uniquely identify slices for a moment in time. UUID plus URN together uniquely identify slices over time, and can be used for forensics, or for use by authorization modules, such as ABAC. UUIDs alone should not be used to identify slices, but only in conjunction with the URN, which scopes the UUID to the authority which generated the UUID. The UUID essentially may only be used to distinguish between slices with identical URNs.
We discussed a couple reasons for this limitation to the use of UUIDs:
- UUIDs are unique to the generator (i.e. the slice authority), not globally. The URN encodes the authority (slice authority in this case). So only the 2 fields together are actually unique. (Assuming of course that authority names are unique...)
- There is an ABAC naming problem. Who is allowed to assert attributes of this ID? It should only be the authority that created the ID. So we want to include the authority whenever referring to the ID. Again, the URN covers this. This is the web certificate authority problem: If someone hacks a small-time but trusted authority in Denmark or wherever, they can issue credentials saying they are google.com. Even if Google actually gets its domain name from some larger more trustworthy authority elsewhere.
If UUIDs were to be centrally registered, such that authorities had to ensure they were globally unique, and authorities registered the associated URN, then you could use some such service to map from UUID to URN, and from URN to a list of UUIDs, at most 1 of which should be currently active. But we aren't requiring any such service.
As far as the AM API is concerned, nothing changes. We still use URN everywhere. This change defines the semantics of the UUID, such that UUID is useful only in the narrow way of distinguishing 2 slices with identical URNs.
Change Set K: Include UUID and email address in slice and user certificates
This is a part of Change Set K which we did not discuss at the AM API session.
After very brief discussion, we adopted the proposal as on the wiki page, to include the UUID and email address in the subjectAltName of both slice and user certificates. These fields may be in any order, comma separated. As with the use of UUIDs for slices, the user UUID should only be used in conjunction with the user URN. However, user URNs are required to be temporally and globally unique. For both UUIDs and email addresses, the 'COPY' tag is not supported.
Note that the slice and user email addresses are addresses for contacting the responsible party - the slice owner or creator and the user. These may be aliases.
Change Set F: Define sliver allocation states and state change methods
At the AM API session, we briefly discussed Change Set F: sliver states and the proposed ActOnSlivers method. Nick Bastin discussed and then circulated an alternative proposal: http://lists.geni.net/pipermail/dev/2012-March/000730.html).
At the coding sprint, we had a long and useful discussion on Nick's proposal, which resulted in agreement on a variant of his ideas. This discussion touched on a number of areas. First there were several overall questions:
- We agreed to use two kinds of states: allocation states, and operational states. We put off discussion of operational states (ie is the node booted), noting however that this is critical.
- We debated whether the API should specify a limited number of states, or allow for aggregate or resource specific states. We agreed that for allocation states, the API should define a limited set of states, while operational states might be more permissive.
- We discussed the pros and cons of including a single all-in-one method to change allocation states, or a single method per desired transition. Rob Ricci noted at least 1 case where there are 2 paths between the same 2 allocation states with very different meaning. As a result, we agreed to use a separate method per allocation state change.
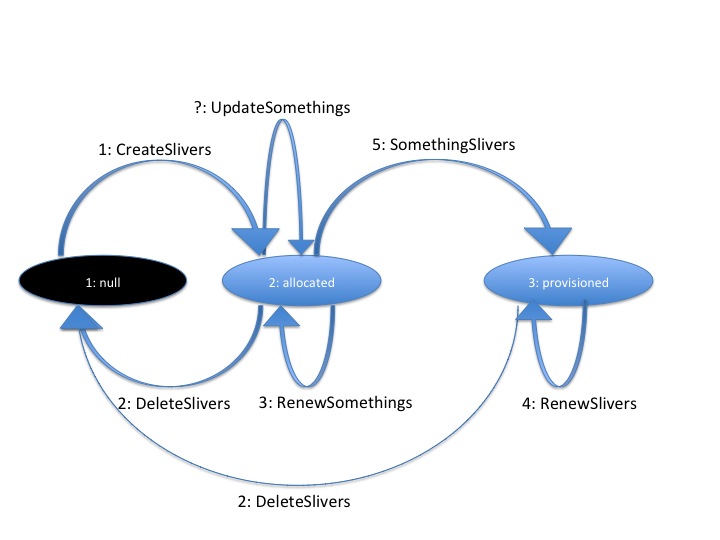
The key result of the discussion was agreement on 3 allocation states for slivers and enumeration of methods for transitioning between those states. We did not select names for the states or the methods. Here is a diagram with placeholder labels for methods and states, which illustrates the decisions described below.

We spent a long time discussing allocation states of slivers. For reference, we looked at Jon Duerig's slides from the AM API session (unpresented). We finally agreed there are 2 or 3 or 4 allocation states for slivers, depending on how you count.
- Start (alternatively called 'null' or 'unallocated'). The sliver does not exist. This is the small black circle in typical state diagrams.
- Allocated (alternatively called 'offered' or 'promised'). The sliver exists, defines particular resources, and is in a sliver. The aggregate has not (if possible) done any time consuming or expensive work to instantiate the resources, provision them, or make it difficult to revert the slice to the state prior to allocating this sliver. This state is what the aggregate is offering the experimenter.
Accepted.We chose NOT to include this intermediary state, occasionally called 'accepted', where the experimenter has accepted the aggregate's offer of resources, but the resources have still not been provisioned.- Provisioned. The aggregate has started instantiating resources, and otherwise making changes to resources and the slice to make the resources available to the experimenter. At this point, operational states are valid to specify further when the resources are available for experimenter use.
Having ruled out the 'accepted' state as unnecessary, we were left with 3 states, the first being the 'null' state. We spent a long time clarifying the semantics of each state, but could not quite agree on names for these states. We took to referring to the states by number, leaving the honor of naming the states to the API documenter.
The key change is the addition of state 2, representing resources that have been allocated to a slice without provisioning the resources. This represents a cheap and un-doable resource allocation, such as we previously discussed in the context of tickets. This compares reasonably well to the 'transaction' proposal written up by Gary Wong (http://www.protogeni.net/trac/protogeni/wiki/AM_API_proposals). When a sliver is created and moved into state 2, the aggregate produces a manifest RSpec identifying which resources are included in the sliver. This is something like the current CreateSliver, except that it does not provision nor start the resources. These resources are exclusively available to the containing sliver, but are not ready for use. In particular, allocating a sliver should be a cheap and quick operation, which the aggregate can readily un-do without impacting the state of slivers which are fully provisioned. For some aggregates, transitioning to this state may be a no-op.
States 2 and 3 have aggregate and possibly resource specific timeouts. By convention the state 2 timeout is typically short, like the redeem_before in ProtoGENI tickets, or the commit_by in Gary's transactions proposal. The state 3 timeout is the existing sliver expiration. If the client does not transition the sliver from state 2 to 3 before the end of the state 2 timeout, the sliver reverts to unallocated. If the experimenter needs more time, the experimenter should be allowed to request a renewal of either timeout. Note that typically the sliver expiration time (timeout for state 3, provisioned) will be notably longer than the timeout for state 2, allocated.
The AM API does not yet have a method for moving from state 2, to state 3. State 3 is the state of the sliver allocation after the aggregate begins to instantiate the sliver. Note that fully provisioning a sliver may take noticeable time. This state also includes a timeout - the sliver expiration time (which is not necessarily related to the time it takes to provision a resource). RenewSlivers extends this timeout. For some aggregates and resource types, moving to this state from state 2 (allocated) may be a no-op.
If the transition from one state to another fails, the sliver shall remain in its original state.
These are the only allocation states supported by this API. Since the state transitions are finite, but include potentially multiple transitions between the same 2 states, this API uses separate methods to perform each state transition, rather than a single method for requesting a new state for the sliver. We did not agree on method names for these transitions (we agreed to leave it as an exercise for the API documenter). Logically however these methods are something like:
- CreateSlivers (name TBD) moves 1+ slivers from unallocated (state 1) to allocated (state 2). This method can be described as creating an instance of the state machine for each sliver. If the aggregate cannot fully satisfy the request, the whole request fails. This is a change from the version 2 CreateSliver, which also provisioned the resources, and 'started' them. That is CreateSlivers does 1 of the 3 things that the similarly-named method did previously.
- DeleteSlivers (name TBD) moves 1+ slivers from either state 2 or 3, back to state 1. This is similar to the AM API version 2 DeleteSliver.
- RenewSomething (name TBD) requests an extended timeout for slivers in state 2 - the allocated but not provisioned state.
- RenewSlivers (name TBD) requests an extended timeout for slivers in state 3 - the provisioned state, as before.
- SomethingSlivers (name TBD) moves 1+ slivers from state 2 (allocated) to state 3 (provisioned). This is some of what version 2 CreateSliver did. Note however that this does not 'start' the resources, or otherwise change their operational state. This method only fully instantiates the resources in the slice. This may be a no-op for some aggregates or resources.
These states apply to each sliver individually. Logically, the state transition methods then take a single sliver URN. For convenience, we agreed to allow a list of sliver URNs, or a slice URN as a simple alias for all slivers in this slice at this aggregate.
Since each method may operate on multiple slivers, each of these methods returns a list of structs as the value:
value = [
{
geni_sliver_urn,
geni_allocation_status,
geni_expires <time when the sliver expires from its current state>,
<others AM or method specific>
<Method 5 SomethingSlivers returns geni_operational_status>
},
...
]
CreateSlivers returns a single manifest RSpec, plus the above list of structs.
We spent a while discussing what it means for an aggregate to operate on multiple slivers at once. Can the aggregate partially succeed? What will experimenters want? We agreed that aggregates must be consistent across all these methods whether they are all or nothing, or support partial success.
These methods all take a new option (aggregates must support it, clients do not need to supply it):
geni_atomic = True/False, default True
If true, the client is requesting that the aggregate either fully satisfy the request, moving all listed slivers to the desired state, or fully fail the request, leaving all slivers in their original state. If the aggregate cannot guarantee all or nothing success or failure given the included slivers and resource types, the aggregate shall fail the request, returning an appropriate error code. If this option is false, then some slivers may transition to the new state, and some note. Aggregates must examine the return closely to know the state of their slivers.
[FIXME: Is this what we agreed to? Or should the default be False? Should there be a !GetVersion option for advertising the AM default?]
Note: CreateSliver remains all or nothing (either the aggregate can allocate all desired resources as requested, or the call fails).
Note: These calls are synchronous - when they return, the slivers shall be in their final state. In particular, the transition from state 2 to 3 (allocated to provisioned) should be quick. The resource that is now in the 'provisioned' state may take a long time to actually be ready for operational use (e.g. imaging and booting the node) -- this remains true as in version 2 after CreateSliver.
SliverStatus, where it currently includes geni_status, shall now return geni_allocation_status with one of the above defined values, and geni_operational_status. The values of geni_operational_status are still under discussion.
Currently, SliverStatus returns a single geni_status for the entire slice at this aggregate. With this change, the top-level allocation status for the slice is not defined, and that field is not required.
Still to do
We may want to add a method for modifying a set of allocated-but-not-provisioned slivers, something like Change Set E's UpdateTicket or Gary's proposal's UpdateTransaction.
The allocation states proposal appears to include semantics sufficient to cover transactions, satisfying our desire for 'tickets'. The ProtoGENI team had agreed to float a proposal for such functionality, and should consider what other functionality or modifications to this proposal, if any is required.
Note that we still intend to discuss new operational states. These will likely be hierarchical, allowing aggregates to use aggregate or resource specific states within the more general GENI wide states. We will define separate methods for transitioning between operational states and for querying the operational state machine for a particular sliver. These states and methods will be used in particular for making a provisioned resource available for operational use (aka StartSliver, for booting a node). Nick Bastin's proposal covers this, but needs to be discussed.
We still want the ability to add or remove individual slivers from a slice. In particular, the ability to supply a single sliver URN to some of the methods as described above suggests that this would be possible. The ProtoGENI team has agreed to float a proposal for supporting this.
We also want the ability to modify an existing sliver, aka UpdateSlivers. The ProtoGENI team has agreed to float a proposal for supporting this.
We noted that these are still changes for AM API version 3. However, we will shortly close down the set of changes for version 3. Further changes will be for a future AM API version 4.
Attachments (1)
- sliver-alloc-states.jpg (50.0 KB) - added by 12 years ago.
{kind=link}
Download all attachments as: .zip