
Opened 12 years ago
Closed 12 years ago
#17 closed (fixed)
Creating a 5 node linear sliver results in geni_status failed
| Reported by: | lnevers@bbn.com | Owned by: | vjo@cs.duke.edu |
|---|---|---|---|
| Priority: | major | Milestone: | |
| Component: | AM | Version: | SPIRAL4 |
| Keywords: | AM API | Cc: | vjo@cs.duke.edu |
| Dependencies: |
Description
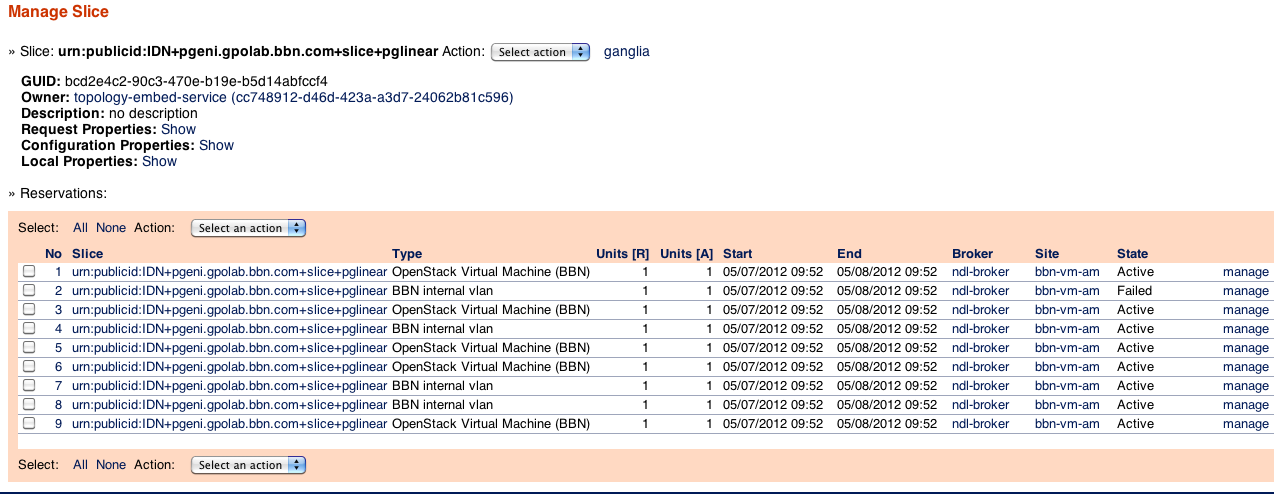
Creating a 5 node linear topology sliver completes with a "geni_status" of "failed".
INFO:omni:{'geni_resources': '',
'geni_status': 'failed',
'geni_urn': 'urn:publicid:IDN+pgeni.gpolab.bbn.com+slice+pglinear'}
Sliver was created around 9:55 and the rspec is attached.
Attachments (2)
{kind=link}
{kind=link}
Change History (15)
Changed 12 years ago by
| Attachment: | Screen shot 2012-05-07 at 10.48.27 AM.png added |
|---|
comment:2 Changed 12 years ago by
Don't forget to take slice down. Orca slices are best-effort - if one sliver fails, the slice will be reported as 'failed' but it may still have components that have succeeded, like in this case.
comment:3 Changed 12 years ago by
Just deleted the sliver to release resources.
Could you elaborate on the "Transient VLAN creation failure". Should I try again?
Changed 12 years ago by
| Attachment: | exo-5vm-linear.rspec added |
|---|
comment:4 Changed 12 years ago by
Tried the 5 node linear topology experiment again. Created the sliver over one hour ago, but the sliver status still shows a 'geni_status' of 'configuring'.
The sliver is 'urn:publicid:IDN+pgeni.gpolab.bbn.com+slice+arendia'.
comment:5 Changed 12 years ago by
| Cc: | vjo@cs.duke.edu added |
|---|
Something is stuck inside OpenStack? for this VM instance for some reason. Please don't touch the slice for now - I'll have Victor take a look at what it is. Basically Orca has issued a command to OpenStack? to start a VM and it never returned. I can see the VM stuck in pending state:
RESERVATION r-u2hsewx9 admin default INSTANCE i-000004be ami-0000000f 10.103.0.3 10.103.0.3 pending geni-orca (admin, bbn-w1) 0 m1.small 2012-05-08T19:33:31Z nova aki-0000000d ari-0000000e
Victor: I can see the start.sh script is still running for it. What I don't see is it killing the instance so it can retry, the way it is supposed to. See if it does that later and if it doesn't, it may be a sign of euca-run-instances call being stuck (should we llook at nginx ?). This is on BBN head node. Please take a look when you have a moment (in the next 24 hours before the slice expires)
comment:6 follow-up: 7 Changed 12 years ago by
| Owner: | changed from somebody to vjo@cs.duke.edu |
|---|
This appears to be a problem with one of the OpenStack? worker nodes. Victor is looking at it.
Note: Until it is resolved, your further experiments may encounter similar problems if your slice happens to hit that worker...
comment:7 Changed 12 years ago by
Replying to ibaldin@renci.org:
Note: Until it is resolved, your further experiments may encounter similar problems if your slice happens to hit that worker...
I believe I have another slice in the same state, it has been in "configuring" state for about 30 minutes. Slice name is "4ringnoip" also in the BBN rack.
comment:9 Changed 12 years ago by
Replying to ibaldin@renci.org:
You can try RENCI rack instead for now...
Yes I am switching to RENCI.
comment:10 Changed 12 years ago by
OK - I have investigated this issue. bbn-w1 (worker 1) experienced a transient communication failure with bbn-hn (head node). As a result, bbn-w1 never received the instruction requesting two of the requested VMs be created. Subsequent VM creation requests did succeed.
Out of an abundance of caution, I have re-started the OpenStack? compute daemon on bbn-w1.
Calls to euca-terminate-instances on the instance IDs stuck in pending *did* succeed, validating this (to me) as merely a communications issue.
A correct solution will involve patching our start script to poll (with a timeout) on VM transition from "pending" to "running", and to terminate VMs that remain in pending state for an "excessive" period of time. Determining what constitutes "excessive" will pose the larger difficulty. ;)
We will work to identify a means of determining whether VM launch is making any headway on the worker node, and will alter our scripts accordingly.
comment:11 Changed 12 years ago by
Was able to run the 5 node linear experiment in the RENCI rack. All nodes were able to successfully exchange traffic.
comment:12 Changed 12 years ago by
I think merely time-limiting the loop I mentioned to some large number of iterations (to accommodate large images) ought to do it. Something like 5 minutes total (at 10 sec. intervals that the script works that would be 30 repeatitions).
comment:13 Changed 12 years ago by
| Resolution: | → fixed |
|---|---|
| Status: | new → closed |
Problem is no longer an issue. Closing ticket.
Slice state snapshot