
Opened 11 years ago
Closed 11 years ago
#89 closed (fixed)
Click router sliver fails at IG Utah 5 out of 6 attempts
| Reported by: | lnevers@bbn.com | Owned by: | somebody |
|---|---|---|---|
| Priority: | major | Milestone: | |
| Component: | Experiment | Version: | SPIRAL5 |
| Keywords: | Cc: | ||
| Dependencies: |
Description
While trying to set up a click router scenario with 3 nodes in the GPO rack and 3 nodes in the Utah rack, 5 out of 6 create sliver attempts result in all nodes in the Utah rack with an geni_status of "notready".
The last attempt was at 8:13 this morning (eastern time), the sliver name is IG-EXP-7. These are the nodes assigned in the Utah sliver:
- pc5.utah.geniracks.net 31548
- pc5.utah.geniracks.net 31546
- pc5.utah.geniracks.net 31547
Attempts at the GPO rack have all been successful.
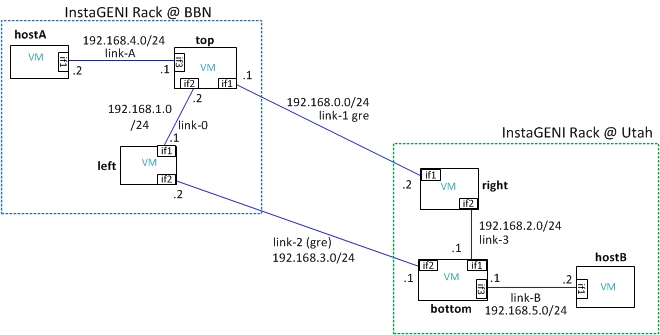
Attaching the RSpec for the topology as well as a diagram that shows the topology of the sliver.
Attachments (2)
{kind=link}
{kind=link}
Change History (5)
Changed 11 years ago by
| Attachment: | IG-EXP-7.jpg added |
|---|
Changed 11 years ago by
| Attachment: | IG-EXP-7.rspec added |
|---|
comment:1 Changed 11 years ago by
comment:2 Changed 11 years ago by
I have another sliver which has a node stuck in geni_status "changing". The sliver was created yesterday on the GPO rack and it is named IG-CT-1. The host is:
pc1.instageni.gpolab.bbn.com port 30779
Not sure if this is related to this ticket, but symptoms are similar.
comment:3 Changed 11 years ago by
| Resolution: | → fixed |
|---|---|
| Status: | new → closed |
The experiment described in the original ticket description has been created several times without any of the nodes failing with a "not_ready" status. This issue is deemed solved, closing ticket.
Capturing resolution information which was exchanged outside the ticket:
On 2/7/13 10:58 AM, Jonathon Duerig wrote:
At last! I think I've finally figured this out.
This has several components:
(1) Some Cisco device on the network is using IP addresses in the 172.17.1.* space. It is responding to arppings sent out by the vnodes. We are using these addresses as unroutable control node IPs. So when we happen to pick one that is in use, the network fails to set up properly because it detects that the address is already in use.
(2) The rc scripts running in the container and the network setup outside of the container are run at the same time. So sometimes one will finish first and sometimes the other one will.
(3) If the outside finishes first, a bridge is established by the time the network sends an arpping to make sure it isn't using a duplicate IP. This will cause network setup to fail.
(4) If the inside finishes first, the IP is established because arppings will not make it outside until the bridge is set up and therefore things work ok.
I've installed a hotfix for this so I can test this out on pc1. I'll be running a sliver many times today to make sure that this is in fact a fix.
In the mean time, perhaps you could investigate why the upstream device is responding to arppings and claiming to have our unroutable IPs.