
| Version 6 (modified by , 12 years ago) (diff) |
|---|
-
Monitoring Architecture
- Document Overview
- Purpose & Scope
-
Use Cases
- Use Case 1: AM Availability
- Use Case 2: Availability/utilization of an aggregate over time?
- Use Case 3: Status of inter-site shared network resources
- Use Case 4: Availability and utilization of inter-site network …
- Use Case 5: What is the state of my slice?
- Use Case 6: State of aggregate utilization at my campus
- Use Case 7: Security complaint from an ISP
- Use Case: Conclusion
- Architectural Overview
- Appendix: Actor, Interface and Data Details
Monitoring Architecture
Version 1.2 June 6, 2012
Document Overview
This monitoring architecture document addresses operational monitoring in the context of GENI.
The members of the GENI federation are highly dependent on each other. Operational monitoring largely consists of cooperatively resolving problems, and this architecture describes the data and interfaces needed for the various participants in GENI to share the information required to solve these problems.
The document is broken into four major sections:
- The first section outlines the purpose and scope of this document and defines monitoring.
- In the second section, seven use cases motivate the subsequent discussion of the monitoring architecture by describing ways it can be used by various members of the GENI community.
- In the third section, the GENI monitoring architecture describes actors who submit and query monitoring data using standard interfaces. In addition, a taxonomy of monitoring data and some principles for collecting that data accurately and ensuring privacy are defined. And finally, there is a discussion of how monitoring relates to policies about troubleshooting and event escalation.
- The fourth section is an appendix containing detailed descriptions of the actors, interfaces, and data.
Purpose & Scope
The purpose of this document is to define a common understanding of GENI monitoring and management and how it relates to other parts of GENI. It is intended to be understandable to both operations and non-operations members of the GENI community.
The scope of the document is monitoring and management as it applies to GENI as a whole and not the standard monitoring done inside aggregates, campuses, and regional and backbone networks. This meta-operations approach to monitoring and management is described in the GMOC Concept of Operations document.
Overview of Operational Monitoring Architecture
The operational monitoring architecture describes operational monitoring use cases which motivate the document and then describes the architecture including various actors, monitoring interfaces, and data collected.
There are different ways of collecting data in GENI and the operational monitoring architecture describes one way of doing so (others include the future GENI Clearinghouse and Instrumentation and Measurement (I&M) infrastructure). In general, there is an authoritative party which is responsible for making each piece of data available. However that data can be shared or cached with other entities that need it. Likewise, there may be several portals or interfaces for accessing and viewing the data, but each portal should retrieve data from its authoritative source.
Path Forward
This document describes the desired end state for operational monitoring to be acheived in Spiral 5. This section explains the current state of these implementations, as of spring 2012, and the path towards that end state.
The GENI Clearinghouse is under development in Spiral 4. Until the GENI Clearinghouse becomes operational, the GPO ProtoGENI Slice Authority (SA) will be monitored and will provide the authoritative user and slice data needed in Spiral 4. When the GENI Clearinghouse becomes operational, it will take over reporting authoritative user and slice data while starting to report authoritative project data.
Slice e-mail is currently supported via standalone scripts that can be run against the various SAs. When the GENI Clearinghouse comes online, it will provide slice e-mail access.
Point of contact and geographical location information are currently collected and maintained by GMOC and stored in the GMOC database. This supports the expected out-of-band contact among various GENI actors.
As per the monitoring architecture, GMOC currently provides a ticketing system and a calendar system for tracking outages.
Aggregates and campuses in the GENI meso-scale currently report data to GMOC using current interfaces. This will continue into the future. As the monitoring interfaces are refined, those deployments will be updated. As new aggregates come online, they will implement these interfaces.
Currently no experimenters submit data to meta-operations (GMOC), but we will work to do this with appropriate interested parties as the need arises.
Instumentation and Monitoring projects are under development in Spiral 4. As they come online they will become consumers of operational monitoring data.
The LLR representative will need remote priviledged access to both GMOC and GENI Clearinghouse data. This mechanism will be worked out in Spiral 5.
The GMOC data interface is in a variety of stages of implementation. The time series interface was implemented and used extensively in Spiral 3. The relational interface is being expanded and deployed in Spiral 4. There are no plans to implement the event interface earlier than Spiral 5.
What is monitoring & management?
Monitoring is the act of collecting data and measuring what is happening.
Management is the act of tracking and fixing problems and responding to requests.
Monitoring and management involve three tasks:
- Observe expected events THEN fix what’s wrong
- Observe unexpected events THEN write procedures for resolving these problems THEN fix what’s wrong (by responding to monitoring)
- Plan for the future: Monitor long-term trends in resource usage THEN provision resources to meet forecasted needs
The purpose of GENI monitoring and management is to share information about GENI current operational status and to increase the amount of time that GENI resources are available and usable by legitimate members of the GENI community.
GENI monitoring and management differs from monitoring and management of other entities. GENI is a set of federated entities managed by different institutions with different policies. The people and information needed to troubleshoot and resolve problems are spread across several physical locations. The users (end users and experimenters), managers and owners of a given piece of equipment may all be different. Finally, interactions between groups are governed by GENI federation agreements (e.g. aggregate provider agreement) and mutual understanding. Since no single party owns all of the parts of the GENI federation, there is a need to coordinate resolution to problems or outages that may occur between any two parts of the federation. This coordination is frequently done via out-of-band communication (phone, email, etc) between the necessary parties.
The meta-operations model assumes that the management of the aggregates, campuses, regionals and core networks which compose GENI is within each entity's own purview. As such this document does not cover any items (like log rotation and following local laws) solely related to the internal monitoring or management of those entities.
Use Cases
The following are a representative set of monitoring use cases. The use cases are not expected to be exhaustive, but they represent what is expected to be used in the Spiral 3-4 time frame. They are intended to show the range of parties which will rely on monitoring and the interfaces and data they need to execute those use cases. In short, these use cases represent the minimum that the architecture must satisfy and provide a sense of how the monitoring architecture will be used.
Each use case includes a brief description of the use case, a list of data that must be collected for the use case, and a list of parties interested in that data.
Use Case 1: AM Availability
Use Case
- Experimenter:
- Creates a slice & slivers at multiple aggregates
- Gets an error using aggregate A
- Sends the error to a GENI experimenter help mailing list
- Experiment support staffers:
- Want to verify the current and recent health of aggregate A
- Is there an obvious problem which explains what the experimenter is seeing?
- Is there a scheduled outage or already existing event that could affect this AM?
Data to collect
- For each GENI aggregate:
- Is it speaking the AM API (up) right now?
- For each resource advertised by that aggregate, is it currently: available, in use, down/missing/unknown?
Interested parties
- Who needs to query this: Everyone might be interested in seeing the health of a GENI resource.
- Who needs to alert on this: Meta-operators. Site operators. Experimenter help providers.
Use Case 2: Availability/utilization of an aggregate over time?
Use Case
- After GEC14, GPO assesses how heavily utilized bare-metal compute resources were between GEC13 and GEC14
- GPO determines if there is generally a shortage of these resources.
Data to collect
- For each GENI aggregate that supports bare metal compute resources, given a custom time period:
- When was the aggregate speaking the AM API (up) during the time period?
- During the time period, how many bare metal resources were: available, in use, down/missing/unknown?
- During the time period, how many slivers that included bare metal resources were active/created at some point during the period?
- (If possible) During the time period:
- How many distinct GENI users had active slivers on the aggregate?
- How many distinct GENI users created slivers on the aggregate?
Interested parties
- Who needs to query this: GPO, prospective experimenters, site operators, meta-operators.
Use Case 3: Status of inter-site shared network resources
Use Case
- A core OpenFlow switch located at NLR in Denver starts misbehaving.
- Its control plane is operating normally, but the data plane appears to drops all traffic on VLAN 3716 (a core shared VLAN).
- This leads to intermittent failures in experiments (traffic through Denver is dropped, traffic along other paths is fine).
- GMOC, GPO, NLR operators and affected site operators gather on IRC to track down the location of the problem, using information about which sites and VLANs have fallen offline.
Data to collect
- For each shared GENI L2 network resource, in particular end-to-end paths between GENI resources:
- Is the network resource reachable (from one or more central locations on the network)?
- What is the utilization of the network resource at the site (bandwidth/packets sent/received, breakdown by type e.g. to detect excessive broadcasts)?
- For each pool of L2 network resources reservable between sites?
- How much of the pool is available/in use/not available?
- Is it possible to allocate and use an inter-site network resource right now (end-to-end test)?
Interested parties
- Who needs to query this: site operators, meta-operators, GPO. It may be useful to active and prospective experimenters.
- Who needs to alert on this: meta-operators and possibly site operators.
Use Case 4: Availability and utilization of inter-site network resources over time
Use Case
- GPO is attempting to learn about per experiment bandwidth utilization over the past year to find out whether GENI experimenters tend to run numerous low-bandwidth experiments, or a smaller number of high-bandwidth ones.
Data to collect
- For each item in the previous use case, track the state over time.
Interested parties
- Who needs to query this: site IT, aggregate owners, meta-operators, GPO.
- Who needs to alert on this: no one.
Use Case 5: What is the state of my slice?
Use Case
- An experimenter has a slice with slivers on many GENI aggregates.
- The experimenter wants to go to one place and get a consistent view of the health and general activity level of his sliver resources.
Data to collect
- Given a slice owned by a GENI experimenter:
- What mesoscale slivers are defined on that slice?
- What is the state of each resource on each sliver (active, down), both now and over the course of the experiment?
- What is the utilization of each sliver resource (as appropriate for its type: active processes, disk space used, flowspace rule count, bandwidth), both now and over the course of the experiment?
Interested parties
- Who needs to query this: active experimenters.
- Who needs to alert on this: perhaps experimenters running services in their slice
Use Case 6: State of aggregate utilization at my campus
Use Case
- An aggregate operator recevies a complaint from campus IT about heavy traffic over the campus control network which seems to be originating from the aggregate operator's lab.
- The aggregate operator wants to quickly determine which if any slivers might be responsible for the traffic.
- If their aggregate does not appear to be causing trouble, Campus IT would like to be able to have some evidence to demonstrate that the slivers on the aggregate are currently sending a typical amount of traffic.
Data to collect
- Given an aggregate:
- What mesoscale slivers are defined on that aggregate?
- What users have active resources on the aggregate right now?
- What is the state of each resource on the aggregate (active, down, in use (by whom)), both now and over the recent past?
- What is the utilization of each aggregate resource (as appropriate for its type: active processes, disk space used, flowspace rule count, bandwidth), both now and over the recent past?
Interested parties
- Who needs to query this: site operators, site IT, meta-operators: site operators need to be able to go one place to answer questions about current activity on the aggregate, in order to be able to answer questions about broken or misbehaving slivers.
- Who needs to alert on this: site operators, meta-operators.
Use Case 7: Security complaint from an ISP
Use Case
- An ISP contacts GENI about concerns that a GENI resource is exhibiting potentially illegal behavior.
- The GENI LLR representative works with GENI Meta-operations as well as the operators of relevant campuses, aggregates, and networks to determine the resource that is the source of the traffic.
- Meta-operations determines what slice is responsible for the traffic from that resource.
- The LLR contacts the owner of the responsible slice (eg using slice e-mail) and determines the nature of the experiment. LLR learns that the experimenter is running a novel protocol which exhibits properties which appear similar to those of some illegal services.
- The LLR contacts the original ISP explaining the experiment thereby resolving the problem.
Data to Collect
- Points of contacts for various groups that are members of the GENI federation
- For a given IP address, which resource and slice does it map to?
Services Needed
- An pseudonymous way of contacting the slice owner (ie slice e-mail)
Interested Parties
- Who needs to query this: Meta-operations and other operators. Perhaps LLR.
- Who needs to alert on this: None. Done on demand.
Use Case: Conclusion
These seven use cases represent the scope of how monitoring will be used in practice and provide context for the monitoring architecture described in the remainder of this document.
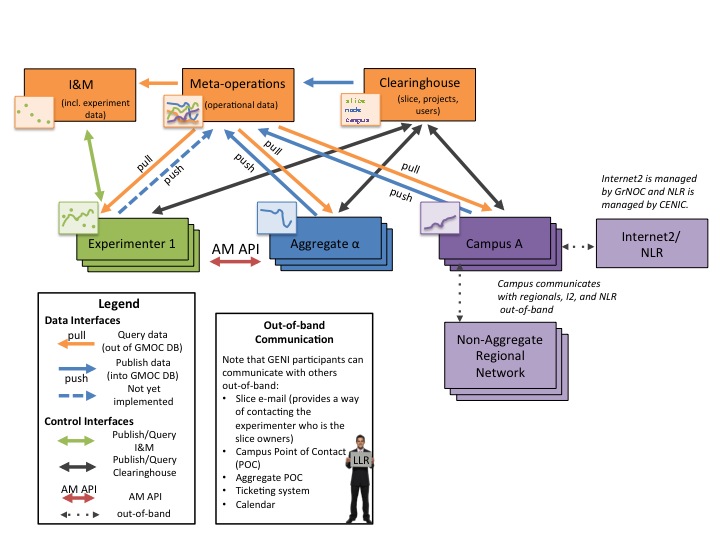
Architectural Overview

The GENI federation includes and interacts with a variety of entities (or actors) which use a small number of standard interfaces to collect and share monitoring and management data. The above picture is a guide to the actors and interfaces that the rest of this document describes. The picture shows how these various entities relate to each other in the context of monitoring.
Meta-operations, the Clearinghouse, and I&M are GENI-wide resources. Meta-operations collects and makes available operational and GENI-wide monitoring data. The future GENI Clearinghouse is the authoritative repository for project, user, and slice information. I&M is the authoritative repository for experiment data.
The blue arrows indicate that aggregates (which contain and operate resources), campuses (which host resources), and experimenters (who use resources and may generate monitoring information) can submit data to meta-operations.
The orange arrows indicate that anyone can query data from meta-operations.
The "out-of-band" communications box shows that experimenters, aggregate operators and campus operators can be contacted out-of-band to help resolve problems.
In addition, GENI monitoring relies on other non-monitoring interfaces. The red arrow shows experimenters reserving resources via the AM API. The black arrows show how authoritative data about slices, projects, and users from the future GENI Clearinghouse is accessed (via interfaces defined by the GENI Architecture group). The green arrow shows the I&M interfaces to support storing experimental data. The dotted arrows indicate that problems between Campuses and their Regional Networks can be resolved via out-of-band access. Likewise, GrNOC manages Internet2 and CENIC manages NLR.
The next three sub-sections describe the actors, interfaces and data in more detail. The three sub-sections after that clarify the relationship with other parts of GENI, describe some principles used to collect and report data used in monitoring, and finally a section related to monitoring and management policy.
Actor Overview
Actors, shown as boxes in the figure, cooperatively share monitoring data within the GENI federation (and outside the federation where appropriate):
- Meta-operations (a.k.a. GMOC) will in the future coordinate GENI-wide operations especially inter-aggregate operations. Note that aggregates and campuses are responsible for operating their own resources.
- The clearinghouse provides a set of services and APIs for the GENI federation and is the authoritative source for information about projects, slices, and users.
- I&M provides a set of services and APIs for the storage and sharing of data (especially experimenter data).
- Aggregates provide resources (e.g. network and compute resources) to the broader GENI community. Examples include: ProtoGENI, PlanetLab, ExoGENI, and InstaGENI. The software which runs an aggregate is known as the Aggregate Manager (AM).
- Campuses host aggregates (or parts of aggregates). Some campuses also operate aggregates in addition to hosting them. Campuses are usually colleges or univeresities, but they may be a city, business, or other administrative entity that owns resources.
- Backbone & Regional Networks are infrastructure that GENI relies on. Some networks (e.g. Internet2 and NLR) participate in GENI. Others (e.g. some regionals) carry GENI traffic but do not participate in GENI directly.
- Experimenters run GENI experiments.
- Legal, Law Enforcement, and Regulatory (LLR) Representative responds to and helps resolve legal, law enforcement and regulatory inquires made to GENI.
Note: The Clearinghouse provides a service which aggregates can use to report information about slices, slivers, and resources to the GENI Clearinghouse. This may not be required for all GENI aggregates, but for simplicity this document assumes this service is being used. If it is not, the same information would need to be obtained from aggregates directly.
Interface Overview
Each of the arrows in the figure represent an interface for sharing data in GENI:
- Query data (out of GMOC DB)
- Anyone <-> Meta-operations
- Anyone can query data from the meta-operations database on demand
- Anyone <-> Meta-operations
- Publish data (into the GMOC DB)
- {Aggregate, Campus, Experimenter, Anyone} <-> Meta-operations
- Aggregates periodically push aggregate data into the meta-operations database.
- Alternatively, meta-operations can periodically pull the same data from the aggregates.
- Campuses and experimenters are allowed (but not required) to publish data the same way aggregates do.
- Anyone can collect GENI-wide data and store it in the meta-operations database.
- Aggregates and Campuses provide Point of Contact and geographic location to GMOC
- {Aggregate, Campus, Experimenter, Anyone} <-> Meta-operations
- Publish/Query Clearinghouse
- Clearinghouse --> Meta-operations
- The clearinghouse provides authoritative data about the existence and names of GENI slices, users, and projects including creation and deletion of the same.
- Experimenters <-> Clearinghouse
- Experimenters register their user accounts at the GENI clearinghouse.
- The clearinghouse provides the experimenter authoritative information about their slices.
- Aggregate Manager <-> Clearinghouse
- Aggregate Managers provide authoritative sliver and node information to the clearinghouse.
- Aggregate Managers can query the clearinghouse for authoritative information about their users and their users' slices.
- Campus <-> Clearinghouse
- Campuses can query the clearinghouse for authoritative information about their users and their users' slices.
- Clearinghouse --> Meta-operations
- Publish/Query I&M
- Experimenter <-> I&M
- Experimenters (and others) use the I&M framework to publish and share data such as experimental results.
- Experimenter <-> I&M
- AM API
- Aggregate Manager <-> Experimenter
- Experimenters use the Aggregate Manager API (AM API) to reserve resources at the aggregate manager.
- Aggregate Manager <-> Experimenter
- out-of-band
- Note: Members of the GENI federation are required to assist the LLR in resolving security incidents. The LLR uses many of the following out-of-band interfaces when resolving problems.
- Anyone -> Experimenter
- Anyone can talk to the experimenter via the slice e-mail address.
- Anyone -> Campus/Aggregates
- Point-of-contact (POC) information provides a way to reach campuses and aggregates
- Campus -> Regionals
- Campuses are responsible for communicating with their regional networks.
- Various Operators -> Backbone Networks
- GrNOC manages Internet2 and CENIC manages NLR.
Data Overview
There are four types of monitoring data collected and stored at meta-operations:
- Aggregate data generated by aggregates
- Campus data generated by campuses
- Slice data generated by aggregates
- Campus network data
- GENI-wide data
In addition, the GENI Clearinghouse collects and stores data:
- includes slice, user, and project information
And finally, the I&M infrastructure collects and stores data.
Information about which resources are reserved in which slices may optionally be reported by the aggregate to the clearinghouse. In the absence of this reporting, aggregates should report this information to meta-operations directly.
Relationships to other parts of GENI
GENI operational monitoring is distinct from but relates to the other parts of GENI including the GENI Clearinghouse and Instrumentation & Measurement.
Relationship between Meta-operations and Clearinghouse
The future GENI Clearinghouse provides a set of services that are key to the running of the GENI federation such as a slice authority, an entity registry, and a logging service. The future GENI clearinghouse is the authoritative source of information about slices, users and projects, entities which are key to the GENI federation. The architecture group has a GENI architecture which defines the clearinghouse services which will provide access to this data. In addition, the GENI Clearinghouse may provide access to other information for which it is not the authoritative source (such as events noting the creation/deletion of slivers) and in the meantime aggregates should report this information directly.
GENI Meta-operations is responsible for operating the GENI federation as a whole (although it is not responsible for operating the individual aggregates, campuses, regional or backbone networks). GENI Meta-operations is the authoritative source for GENI-wide monitoring data (e.g. end-to-end connectivity across GENI). In addition, meta-operations is the authoritative source of monitoring data provided by aggregates, campuses and experimenters (when appropriate). For example, this includes current and historical statistics about nodes (operational state, memory/disk usage) and networks (operational state, data rate). Also, GENI Meta-operations correlates information from the Clearinghouse (eg slice creation and deletion times) when it helps clarify monitoring data.
The monitored data accessible from meta-operations is invariably collected by measuring the state of the world (for example, by polling a node periodically to see if it is operational) whereas the data via the GENI Clearinghouse is based on transitions (for example, an aggregate informs the GENI Clearinghouse about the creation of a sliver at its aggregate, for which it definitively knows the resource allocated, the creator, and the creation time).
Relationship between Monitoring and Instrumentation & Measurement
Instrumentation and Measurement (I&M) collects data of use to experimenters, especially experiment data. I&M can pull operational data of interest from the GMOC database.
Monitoring Data
GENI monitoring data can be broken down into a small number of types of data which must be collected in a consistent manner so that the data can be shared and meaningfully used by various parties throughout GENI. Meta-operations must take reasonable steps to protect the privacy of some data (e.g. user data that identifies individuals) in collection, storage, and publishing functions.
Types of Data
There are multiple ways of describing the data used in monitoring.
The structure of the data falls in one of three categories: time series data, relational data, and event data.
Time series data is a particular piece of numeric data measured over time. An example of time series data is the number of bytes sent on an interface over a series of adjacent 30 second time periods.
Relational data conveys entities and the relationship between them. An example of relational data is that "slice S contains resource R".
Event data denotes something happening or being noticed at a particular moment in time. An example of an event is "slice S was created at time T" or "the data rate on interface I exceeded threshold H at time T".
The accuracy of the data can be described as either: transition-based or sampled.
transition-based data, like that made available by the GENI Clearinghouse, is data based on the knowledge of the entities being created or destroyed. An example of transition-based data is "slice S was created at time T by user U".
Sampled data, like that made available by GENI Meta-operations, is collected by measuring the state of the world periodically. An example of sample data is the availability of an interface over time.
In addition, data has an authoritative source such as the GENI clearinghouse, meta-operations, or I&M.
The GENI clearinghouse is the authoritative source for information about GENI primitives like slices, projects, and users and event information about the creation and deletion of those same primitives.
Meta-operations is the authoritative source for operationally critical data from various aggregates and campuses. Examples of data stored in meta-operations are polled cpu usage and interface statistics on GENI compute resources.
Instrumentation & Measurement is the authoritative source for data collected in the course of individual experiments.
Consistent Naming and Definitions of Data
In order for monitoring data to be useful in the shared environment of GENI, data in the GMOC database needs to have a consistent meaning both in the name of the data and the definition of said data. For example, if interface counters from switches at different campuses are stored with different names it may be difficult to find and easily compare the traffic rates at various points in the network. Likewise, if some interfaces report byte counters over an interval and others report current data rates, then the comparison between these two items may not be accurate or simple.
This means that data that is published to the GMOC database should use a naming system that is consistent across data submitters in two ways:
- the names of the data reported and stored in the database should be consistent regardless of who reports the data, and
- the definition of the data reported should be consistent regardless of who reports the data.
Consistent Naming of GENI Resources and Devices
Many GENI resources may need to be referenced by multiple parties, therefore the names used to identify them need to be consistent regardless of who is submitting the data.
For example, two aggregates might need to refer to the same switch or two endpoints of the same network link.
In addition, it is possible for a member of GENI to submit interesting data about another part of GENI and therefore it is important for the name of the resources to be consistent in order for that data to be useful. For example, meta-operations could run a test to see if each aggregate manager (AM) responds to a basic AM API call to determine that the AM is up and responding to requests. In this case, meta-operations needs to identify the aggregate it is testing by the same name the aggregate uses to describe itself when submitting their own monitoring data.
Where they are guaranteed to be unique, URNs should be used to describe items like users and aggregates. In some circumstances, URNs are not unique, and in these cases URNs combined with another identifier should be used. For example, AM API v3 will ensure that slices can be identified by the combination of a slice URN and a UUID which together are globally unique. Names defined by equipment manufacturers should be used where appropriate (MAC addresses, interface names, etc). Finally if none of these identifiers are appropriate, a consistent naming scheme is chosen leveraging naming schemes defined elsewhere in GENI (such as RSpecs and I&M data definitions) where possible.
Privacy
Monitoring data may potentially contain private information which could be used to:
- identify an experimenter
- identify important aspects of experiments (such as experiment topology)
On the other hand, because GENI is inherently a shared resource, monitoring information must be shared. For example, knowing the CPU load on a machine hosting many virtual machines could help ascertain the cause of problems on multiple experiments.
Therefore there is an inherent tension between keeping information private and making it public. We choose to divide data into three categories and clearly inform all parties (meta-operations personnel, aggregate and campus operators, experimenters) about the privacy of particular types of data. It is the responsibility of all of these parties to work to use and share data appropriately. There are three types of data:
- Some data CAN be shared publicly including:
- existence of slice, its name, and its identifiers (URN, UUID), and
- slice is active (has resources)
- Some data CAN be shared IF the data is protected by access controls.
- Some data should NOT be shared publicly including:
- opt-in user data
- data that identifies experimenters by username/real name
- data that identifies experimenter contact info.
GENI experimenters should be warned that their slice name is public. Experimenter credentials may contain the user e-mail and this may be shared with aggregates they are using and with GMOC, but should not be shared outside GMOC. In addition, basic information about an experiment (eg nodes used, interface stats) will be publicly available as it may be needed to debug GENI-wide problems as well as issues with individual experiments.
Individual organizations should follow their own privacy policies in determining what to share.
Finally, the LLR's access to data is controlled by the LLR policy which supersedes anything written here.
Accountability Report
Meta-operations should make available a summary of statistics about each aggregate and campuses to aid local operators in determining whether a problem might be originating at their aggregate/campus or elsewhere.
The accountability report should include the data listed in Use Case 6: State of Aggregate Utilization at My Campus.
Policy
GENI policy exists to increase the availability of resources for experimenters. Being able to communicate with various parts of GENI to resolve technical and security problems increases the availability of resources for everyone. The monitoring infrastructure must be consistent with and support GENI policy. In particular, slice e-mail and aggregate and campus points of contact make it possible to troubleshoot problems and handle emergency situations.
This section goes over various policies and how monitoring related to them.
Verification of Data Collection
In addition to data being collected with a consistent name and meaning as well as through a consistent mechanism, that the data continues to be successfully collected should regularly be verified and outages should be promptly debugged.
Troubleshooting & Event Escalation
In order to resolve both troubleshooting and security problems, meta-operations, aggregate operators, campuses, and experimenters must work together.
To facilitate this, aggregates must advertise their resources accurately. At a minimum aggregates must advertise their resources on an aggregate wiki page. It is preferred that they advertise their resources via the AM API.
Aggregates and campuses should keep their point of contact information up-to-date.
Experimenters should respond to emails sent to their slice e-mail address.
All parties should cooperate with meta-operations and the LLR on the resolution of security events in a manner consistent with policies defined elsewhere.
Emergency Stop
On occasion, meta-operations may identify a problem which may require one or more experiments to be stopped.
In the event of a issue, meta-operations may contact:
- aggregates and campuses via their Point of Contact information, and
- experimenters via slice e-mail.
As a last resort, meta-operations may shutdown resources on one or more slices via a call to the AM API or disconnect aggregates or campuses which seem to be the source of the problem.
The Emergency Stop document describes this procedure and is updated periodically.
Policy
In addition to following local policy, members of the GENI community should follow policies that relate to them such as:
- the Aggregate Provider Agreement,
- the LLR,
- all privacy policies,
- ethical experimentation policies, and
- other policies as they come into effect.
Organizations should follow best practices (eg for security, logging, and backups) which if not followed would affect other members of the GENI community.
Security
The role of security in monitoring and management is to prevent the compromise of GENI resources and to prevent the use of GENI resources to compromise other entities. Meanwhile, we should allow interesting research which may require experimenters and operations to coordinate.
GENI operators should follow best practices to hinder compromise and also detect and respond to successful compromise. GENI experimenters should notify meta-operations if they are doing something which could be dangerous or cause an outage so that this can be tracked like other outages. Monitoring should not introduce security concerns (eg by overloading a resource), and may help to detect potential security issues (eg outdated software).
Architectural Overview: Conclusion
The members of the GENI federation are highly dependent on each other. Operational monitoring largely consists of cooperatively resolving problems and this architecture describes the data and interfaces needed for the various actors to share the information required to do so.
The individual members of the GENI federations (aggregates, campuses, experimenters) shown in the figure are responsible for providing monitoring data about themselves to meta-operations. Likewise, the GENI Clearinghouse provides authoritative information about slices, projects, and users to meta-operations.
Meta-operations makes the time series, relational and event monitoring information collected from these sources, combined with intra-GENI monitoring, available to members of the GENI federation.
In addition, there are various out-of-band interfaces available for coordinating with entities that are not part of the GENI federation (such as regional networks) as well as for communicating with people who are responsible for slices as well as aggregate and campus operators.
Data should be collected in a consistent manner taking care to ensure the privacy of data where appropriate.
Monitoring should be done in a manner consistent with GENI policies including maintaining point of contact information used in troubleshooting and emergency stop.
Appendix: Actor, Interface and Data Details
The following sections provide more detail about the items described in the Actor, Interface, and Data sections above.
Actors
Each of the actors in the monitoring architecture described previously are described below in more detail.
The descriptions include a definition of the actor, the operator of that actor (where appropriate), a list of the interfaces used by this actor, the data items that it both generates and stores, and any services provided to others.
Meta-operations
Definition: Meta-operations (a.k.a. GMOC) coordinates GENI-wide operations with a focus on inter-aggregate operations. (Note that aggregates and campuses are responsible for operating their own resources.)
Operator: Indiana University GrNOC (currently)
Interfaces:
- Anyone <-> Meta-operations
- {Aggregate, Campus, Experimenter, Anyone} <-> Meta-operations
- Clearinghouse --> Meta-operations
- Out-of-band interface: Anyone --> Experimenter
- Out-of-band interface: Anyone --> {Campus, Aggregate}
Note: Meta-operations supports the Anyone --> Experimenter and Anyone --> {Campus, Aggregate} interfaces by keeping track of the appropriate contact information and making it accessible to people with appropriate permissions.
Authoritative Source of Data Items: GENI-wide monitoring data; monitoring data from each aggregate in GENI
Services or visualizations provided:
- Web interface for operators
- Web interface for experimenters
Clearinghouse
Definition: The Clearinghouse provides a set of services and APIs for the GENI federation and is the authoritative source for information about projects, slices, and users.
Operator: The long term operator of the Clearinghouse has not yet been determined.
Interfaces:
- Clearinghouse --> Meta-operations
- Experimenter --> Clearinghouse
- Aggregate --> Clearinghouse
- Campus --> Clearinghouse
Authoritative Source of Data Items: Slice, user, and project information.
Data items which is a trusted repository for: The Clearinghouse provides a service which aggregates can use to report information about slices, slivers, and resources on those to the GENI Clearinghouse. This may not be required for all GENI aggregates, but for simplicity this document assumes this service is being used. If it is not, the same information would need to be obtained from aggregates directly.
Services or visualizations provided:
- Services listed in the Clearinghouse Architecture
I&M
Definition: Instrumentation and measurement provides a set of services and APIs for members of the GENI community (especially experimenters) to archive data and make it available for others to use. I&M services are defined by the I&M working group.
Interfaces:
Services or visualizations provided:
- A variety of data archival, location, and sharing services.
Aggregate
Definition: Aggregates provide resources (e.g. network and compute resources) to the broader GENI community. Examples include: ProtoGENI, PlanetLab, and OpenFlow. (Aggregates may be distributed over widely separated physical locations and operated by different organizations, unlike campuses.)
Note that in particular, each GENI rack (such as ExoGENI and InstaGENI) is an aggregate.
Operator: Aggregate operators (like ProtoGENI, PlanetLab, and Orca) or campuses.
Interfaces:
- Aggregate <-> Meta-operations
- Aggregate --> Clearinghouse
- Aggregate Manager <-> Experimenter
- Out-of-band interface: Anyone --> {Campus, Aggregate}
Data items sourced: All data about this aggregate and its resources.
Data items which is a trusted repository for: None
Services or visualizations provided:
- Varies. Some aggregates provide extensive monitoring and visualization while others provide very little.
Campus
Definition: Organization and equipment on a campus that hosts GENI resources, aggregates, or parts of aggregates. Some campuses also operate aggregates in addition to hosting them. Campuses are usually colleges or univeresities, but they may be a city, business, or other administrative entity that owns resources.
Operator: Campus IT
Interfaces:
- Campus <-> Meta-operations
- Campus --> Clearinghouse
- Campuses communicate with regional networks out-of-band as needed
- Out-of-band interface: Anyone --> {Campus, Aggregate}
Data items sourced: Data about this campus.
Data items which is a trusted repository for: None
Services or visualizations provided:
- Varies.
Experimenter
Definition: Experimenter runs GENI experiments.
Operator: Self
Interfaces:
- Experimenter <-> Meta-operations
- Experimenters --> Clearinghouse
- Aggregate Manager <-> Experimenter
- Experimenter <-> I&M
Data items sourced: Data about this experiment. Not all experiments should provide data to meta-operations. Appropriate experiments to provide data to meta-operations are those which would be insightful for other experimenters or operators (for example, a experiment which monitored the connectivity of the GENI core would be appropriate).
Experimental data itself is stored by I&M.
Data items which is a trusted repository for: None
Services or visualizations provided:
- Varies.
Other Infrastructure
I2/NLR and Regionals
Definition: Infrastructure not listed elsewhere that GENI relies on. Some networks (e.g. Internet2 and NLR) participate in GENI. Others (e.g. some regionals) carry GENI traffic but do not participate in GENI directly.
Operator: Self
Interfaces:
- Campuses communicate with regional networks out-of-band as needed
- Internet2 is managed by GrNOC and NLR is managed by CENIC.
Data items sourced: Infrastructure which is a participant in GENI might make data available, but infrastructure which is not part of GENI will likely not make data available.
Data items which is a trusted repository for: None
Services or visualizations provided:
- None required.
Legal, Law Enforcement, and Regulatory (LLR) Representative
Definition: The person responsible for responding to and resolving legal, law enforcement, and regulatory requests made to GENI. The LLR Representative is also known as the LLR.
Operator: LLR Representative is a person.
Interfaces:
- Communicates with experiments via slice e-mail: Anyone --> Experimenter
- Communicates with campuses and aggregates via their Point of Contact information: Anyone --> {Campus, Aggregate}
References: LLR document
Interfaces
The monitoring actors share information using the interfaces identified previously and described below in more detail.
The interfaces are grouped according to the legend in the Architecture figure (eg the "Publish Data" section includes interfaces shown in blue in the figure).
Each interface includes a description, whether the interface is push/pull, a list of data shared over this interface, the data format, the frequency of update and the purpose of the interface.
Query data (out of GMOC DB)
Interface: Anyone <-> Meta-operations
- Description:
- Anyone can query data from the meta-operations database on demand
- Push/pull: pull
- Data:
- On demand, query any time series, relational, or event data allowed by the privacy policy:
- Frequency of update: on demand
- Purpose: Allows any entity to pull monitoring data from the meta-operations database.
Publish data (into the GMOC DB)
Interface: {Aggregate, Campus, Experimenter, Anyone} <-> Meta-operations
- Description:
- Aggregates periodically push data into the meta-operations database
- Alternatively, meta-operations can periodically pull the same data from the aggregates
- Campuses and experimenters may use the same interfaces that aggregates use to publish data to the meta-operations database.
- Anyone can perform GENI-wide monitoring and publish the results in the meta-operations database
- Aggregates periodically push data into the meta-operations database
- Register the following information at meta-operations:
- aggregate/campus point of contact
- aggregate/campus geographical location
- Push/pull: push to meta-operations (or optionally meta-operations can pull this data periodically or on demand)
- Data: Periodically push any time series, relational, or event data with some consistent granularity (eg submit data collected at 30 second intervals every 5 minutes).
- Data format: Currently, time series data is submitted via XML file defined by GMOC (script).
- Frequency of update: Currently updated every 5 minutes with data granularity of 30 seconds.
- Purpose: Allows aggregate, campus or experimenter to push monitoring data into the meta-operations database.
- Notes: Alternatively, GMOC can use nearly the same interface to pull the data from the aggregate.
- Variations
- Data source: Aggregate Manager (AM) / Data sink: Meta-operations
- Data source: Campus / Data sink: Meta-operations
- Data source: Experimenter / Data sink: Meta-operations
Publish/Query Clearinghouse
Note: All interfaces involving the Clearinghouse will be defined by the clearinghouse architecture and related documents.
Interface: Clearinghouse --> Meta-operations
- Description:
- The clearinghouse provides authoritative data about GENI entities (slices, users, aggregates) including their existence, their creation and deletion, and the relationship between the same.
- Data:
The clearinghouse provides:
- authoritative slice, user and project data (including meta-data and historical data about the same),
- a list of aggregates
- a list of services
- and may provide a copy of resource information for some aggregates and a mapping between slice, user, and resource information.
- Purpose: Allows meta-operations to get authoritative slice, user, and project info from the clearinghouse. Also allows access to sliver information from aggregates which provide it to the Clearinghouse.
Interface: Experimenters <-> Clearinghouse
- Description:
- Experimenters request the generation of user and slice credentials and information at the clearinghouse.
- The clearinghouse provides the experimenter information about
their slices (and optionally about their slivers and nodes).
- In particular, the clearinghouse knows about creation and deletion of user, slice, and project information (and meta-data about the same).
- Push/pull: Push
- Data:
- list of experimenter's slices (including meta-data)
- (optionally) list of slivers in experimenter's slice (including meta-data)
- Data format: TBD by clearinghouse architecture
- Frequency of update: on demand
- Purpose: Experimenter can query the clearinghouse for information about slices which they have access to.
Interface: Aggregate Manager <-> Clearinghouse
- Description:
- Optionally Aggregate Managers provide sliver and node
information to the clearinghouse.
- In particular, AMs can optionally provide information to the clearinghouse such as: a sliver was created/deleted (and the time of that operation); nodes were added/removed from a sliver (and the time of that operation); a slice at an AM was shutdown (and the time of that operation).
- Optionally Aggregate Managers provide sliver and node
information to the clearinghouse.
- Data:
- (optionally) list of slivers in each slice and time sliver was created/deleted
- (optionally) list of nodes in each sliver and time node was added/removed
- (optionally) list of shutdown slivers and time shutdown was executed
- Purpose: The clearinghouse stores an optional copy of information about slivers and an optional mapping between slivers and nodes.
Interface: Campus <-> Clearinghouse
- Description:
- Campuses can access information stored at the Clearinghouse.
- Data:
- list of users at campus
- list of slices at campus
- (optionally) list of slivers in each slice and time sliver was created/deleted
- (optionally) list of nodes in each sliver and time node was added/removed
- (optionally) list of shutdown slivers and time shutdown was executed
- Purpose: Allows campuses to access information stored at the Clearinghouse.
Publish/Query I&M
Interface: Experimenter <-> I&M
- Purpose: Allow members of the GENI federation to share arbitrary data.
AM API
Interface: Aggregate Manager <-> Experimenter
- Purpose: Experimenters use the AM API to reserve resources at the aggregate manager (i.e. to create a sliver)
- Push/pull: push
- Data:
- advertisement RSpec (contains a list of nodes at AM)
- manifest RSpec (contains a list of nodes in a slice)
- Data format: XMLRPC over HTTPS
- Frequency of update: On demand.
Out-of-band
Interface: Anyone -> Experimenter
- Description:
- A slice e-mail provides a way for anyone to talk to the experimenter(s) responsible for a slice.
- Notes: This slice e-mail is recommended by the LLR.
Interface: Anyone -> Campus/Aggregates
- Description:
- Point-of-contact (POC) information provides a way to reach campuses and aggregates via e-mail or telephone. This information is not public, but is made available to those with appropriate permissions.
- Data:
- e-mail of campus/aggregate point of contact
- telephone number of campus/aggregate point of contact
- Frequency of update: As needed
Interface: Campus -> Regionals
- Description:
- Campuses are responsible for communicating with regional networks, if they aren't part of GENI.
Interface: Various operators -> Backbone Networks
- Description:
- Internet2 is managed by GrNOC and NLR is managed by CENIC.
Data
The monitoring actors and interfaces share data identified previously and described below in more detail.
It is impossible to detail all data which might be collected to use for monitoring in GENI. The following list aims to provide a fairly minimal baseline of data that should be collected in Spirals 3 and 4 and which satisfies the use cases described previously. Note that the format of the data may be interface specific.
GENI-wide data
The following data primarily describes the health of various GENI resources:
- GENI aggregate is speaking the AM API right now. Plus historical versions of this info.
- GENI aggregate is able to execute major element of the sliver creation workflow via the AM API right now. Plus historical versions of this info.
- For each L2 network resource, is the network resource reachable (from one or more central locations on the network)?
- For each pool of L2 network resources reservable between sites, is it possible to allocate and use an inter-site network resource right now (end-to-end test)? Plus historical versions of this info.
- Health data about the control plane (e.g. how full is the myplc's disk as opposed to how full is the plnode's disk)
Aggregate data
For each aggregate:
- Find active/created slivers on aggregate. Plus historical versions of this info.
- Find active users on aggregate.
- Find the state of resources (available/in use (by whom)/down/missing/unknown) on aggregate. Plus historical versions of this info.
- Find the utilization and history of resources on aggregate (as appropriate for its type: active processes, disk space used, flowspace rule count, bandwidth). Plus historical versions of this info.
- Find distinct GENI users who had active slivers (or created slivers on said aggregate). Plus historical versions of this info.
- point of contact
- geographical location
Campus data
For each campus:
- point of contact
- geographical location
Could also upload:
- campus equipment status
In addition, logs should be kept and made available on request.
L2 Network Resources Data
For each L2 network resource:
- Utilization of the network resource at the site (bandwidth/packets sent/received, breakdown by type e.g. to detect excessive broadcasts)?
For each pool of L2 network resources reservable between sites:
- Portion of the pool that is available/in use/not available? Plus historical versions of this info.
Slice data
Given a slice owned by a GENI experimenter:
- Find resources on slice.
- Find state of resources on each sliver (active/down). Plus historical versions of this info.
- What is the utilization of each sliver resource (as appropriate for its type: active processes, disk space used, flowspace rule count, bandwidth). Plus historical versions of this info.
Clearinghouse Data
Data collected at the Clearinghouse:
- slice information (name, creation/deletion/shutdown times)
- users
- projects
- slivers (optional)
- nodes (optional)
- relationship between the above items
- list of services provided by the clearinghouse
Information about which resources are reserved in which slices may optionally be reported by the aggregate to the clearinghouse. In the absence of this reporting meta-operations can observe this information.
I&M Data
- Experiment data
Attachments (1)
- MonitoringArchv7.jpg (89.7 KB) - added by 12 years ago.
{kind=link}
Download all attachments as: .zip