
-
GENI AM API Changes from version 2 to version 3
- Summary of Changes
- Adopted Change Details
- Addressable Slivers
GENI AM API Changes from version 2 to version 3
This page documents changes to the GENI Aggregate Manager API from version 2 to version 3. It consists of the text describing the changes to the API which was used to define and adopt the changes to the API for version 3.
- Version 2 of the GENI Aggregate Manager API
- Version 3 of the GENI Aggregate Manager API
- Draft changes to the GENI Aggregate Manager API for future versions. That is where this text originally was written.
Summary of Changes
This version of the AM API includes multiple changes since version 2 of the AM API. For experimenters, a few things are worth noting:
- The old
CreateSliveroperation has now been broken into 3 steps:Allocateto reserve the resourcesProvisionto instantiate the resources, which may take time to completePerformOperationalAction(geni_start)to start (e.g. boot) the resources, which also may take time to complete
- Use the new intermediate
geni_allocatedstate afterAllocateto coordinate reservations across aggregates, e.g. to ensure another aggregate can give you nodes to be the other end of a requested link. - Multiple methods have been renamed, typically by removing the
Sliverterm from method names. - Sliver expiration is available in the return from multiple other methods, like
Provision - You no longer use
ListResourcesto see the contents of your slice - useDescribeinstead.ListResourcesis only for the AM's Ad RSpec. - Experimenters can select when to start or stop resources, e.g. when to boot a VM. Consult the operational state machine in the AM's Ad RSpec, and use
PerformOperationalAction. - SSH login names and keys should be available in manifest RSpecs in a standard format.
- Slice name restrictions have been codified and standardized.
- Slice names are <=19 characters, only alphanumeric plus hyphen (no hyphen in first character):
'^[a-zA-Z0-9][-a-zA-Z0-9]+$'
- Slice names are <=19 characters, only alphanumeric plus hyphen (no hyphen in first character):
Tool developers should also be aware:
- The
credentialsargument to methods is now a struct, including a type and version for each credential. AMs should advertise which credential types they accept. SAs should advertise which type they provide. - Aggregates may have their own operational states and actions. The Ad RSpec should define these, probably by
sliver_type.
Listing of the Change Sets:
- Change Set D: Slivers: Change methods to clarify that there may be multiple slivers per slice at an AM, and to allow operating on individual slivers
- Change Set F3: Sliver Allocation States and methods
- Change Set F4: Method to perform Sliver Operational actions
- Change Set F5: Sliver Operational States
- Change Set G: Generalize the credentials argument, allowing ABAC support
- Change Set I1: SliversStatus return structure includes sliver expiration
- Change Set I2: SliversStatus return includes SSH logins/key for nodes that support SSH access
- Change Set I3: CreateSlivers return becomes a struct, adds sliver expiration
- Change Set K: Standardize certificate contents, etc.
- Include a real serial number, holder email, holder uuid, and optionally authority URL in certificates
- Define slice ID as the UUID plus URN in slice certificates
- Define slice name, sliver name, and user name restrictions, and similar for URNs
- Publish schemas for credentials and certificates
- Change Set M: New method signatures, incorporating all other adopted change sets
Adopted Change Details
Change Set D: Sliver-specific operations
A slice may have multiple slivers at a single AM. Experimenters can operate on slivers independently, if the AM supports it. AMs define slivers as groups of resources, and give them locally unique sliver_urns for identifying that group of resources.
This change was briefly discussed at GEC13, and remains open for discussion.
See http://lists.geni.net/pipermail/dev/2012-March/000593.html as well.
Motivation
This change set was discussed at the GEC12 AM API session.
The current AM API calls take a Slice URN, and operate on all resources under that label at the given aggregate - all the resources for that slice at the aggregate are allocated, renewed, and deleted together. There is no provision for releasing some of the resources allocated to the slice at that aggregate, or for adding new resources to the reservation for that slice at a given aggregate.
This ties closely to the precise definition of a Slice vs a Sliver. The current AM API methods imply that a sliver represents all resources at an aggregate for a given slice. However, this does not match the definition that previous GENI documents have used, nor the functionality that experimenters desire.
Previous GENI documents have used this definition: A sliver is the smallest set of resources at an aggregate that can be independently reserved and allocated. A given slice may contain multiple slivers at a single aggregate. A sliver may contain multiple components.
Given this definition, the current AM API methods in fact operate on a group of slivers.
This change set provides a means for experimenters to operate on individual slivers within their slice at a given aggregate.
Define sliver
A Sliver is an aggregate defined grouping of resources within a slice at this aggregate, whose URN identifies the sliver, and can be used as an argument to methods such as Delete or Renew, and whose status can be independently reported in the return from SliversStatus. The AM defines 1 or more of these groupings to satisfy a given resource request for a slice. All reserved resources are directly contained by exactly 1 such sliver container, which is in precisely 1 slice.
Slivers are identified by an aggregate selected URN. See other change proposals for details on standardizing such URNs.
Addressable Slivers
Considering the clarified sliver definition, several API names are misleading. This change proposal modifies those method names to clarify that they may work with multiple slivers. Additionally, some methods can logically operate on individual slivers: this change modifies those methods' arguments to allow specifying a particular sliver.
- Rename some existing methods to clarify that they act on 1+ slivers:
- CreateSliver -> Allocate, Provision (see below)
- RenewSliver -> Renew
- DeleteSliver -> Delete
- SliverStatus -> Status
- Some methods that take
slice_urnnow take aurnthat may be a slice or sliver:- E.G.
Renew,Delete,Status - AMs are responsible for distinguishing whether the request operates on a slice or a sliver (see Change Set K which defines how slice and sliver URNs differ).
- AMs are free to refuse to
Renew,Delete, or provide status on an individual sliver, if the local AM or that resource type does not support it.- AMs should return an error message if the operation is not supported.
- See below for ways that aggregates advertise their supported behavior.
- E.G.
- Define new returns from GetVersion, for specifying the semantics of operating on individual slivers.
These returns are only required if the aggregate supports non-standard behavior. Aggregates that support the default behavior may omit these GetVersion returns.
geni_single_allocation: <XML-RPC boolean 1/0, default 0>: When true (not default), when performing one of (Describe,Allocate,Renew,Provision,Delete), such an AM requires you to include either the slice urn or the urn of all the slivers in the same state. If you attempt to run one of those operations on just some slivers in a given state, such an AM will return an error.
For example, at an AM where geni_single_allocation is true you must Provision all geni_allocated slivers at once. If you supply a list of sliver URNs to Provision that is only 'some' of the geni_allocated slivers for this slice at this AM, then the AM will return an error. Similarly, such an aggregate would return an error from Describe if you request a set of sliver URNs that is only some of the geni_provisioned slivers.
geni_allocate: A string, one of fixed set of possible values. Default isgeni_single. This option defines whether this AM allows adding slivers to slices at an AM (i.e. callingAllocate()multiple times, without first deleting the allocated slivers). Possible values:geni_single: Performing multipleAllocates without a delete is an error condition because the aggregate only supports a single sliver per slice or does not allow incrementally adding new slivers. This is the AM API v2 behavior.geni_disjoint: Additional calls toAllocatemust be disjoint from slivers allocated with previous calls (no references or dependencies on existing slivers). The topologies must be disjoint in that there can be no connection or other reference from one topology to the other.geni_many: Multiple slivers can exist and be incrementally added, including those which connect or overlap in some way. New aggregates should strive for this capability.
Note that these options interact with geni_best_effort defined in Change Set F3, defining whether operations on a set of slivers (or whole slice) should either all fail/succeed together, or if some slivers can succeed and others fail. Default behavior is false - all slivers succeed or all fail. If the aggregate cannot guarantee all or nothing success or failure given the included slivers and resource types, the aggregate shall fail the request, returning an appropriate error code. If this option is true, then some slivers may transition to the new state, and some not. Experimenters must examine the return closely to know the state of their slivers - such methods will return data about all requested slivers. Aggregates may optionally return geni_error for each sliver for which the operation failed, to indicate further details. Note that Allocate is always all-or-nothing.
It is expected that many aggregates will implement one of the following combinations of options:
geni_best_effort= true,geni_allocate=geni_many,geni_single_allocation= false (E.G. FOAM, PlanetLab)geni_best_effort= false,geni_allocate=geni_disjoint,geni_single_allocation= true (E.G. ProtoGENI)
Change Set F: Support AM and resource-type specific methods.
Define the control API (the AM API) as about moving slivers through various states at an AM.
The proposal originally here elicited concerns (the method ActOnSlivers is an ioctl, and the states mix allocation and operational states).
A later alternative proposal was proposed via email: http://lists.geni.net/pipermail/dev/2012-March/000721.html
At the GEC13 coding sprint, a variant on the above was approved. It is documented here as Change Set F3.
A variant on the operational states proposal is defined as Change Set F4 and documented here: https://openflow.stanford.edu/display/FOAM/GENI+-+PerformOperationalAction
Motivation
AM API methods logically change the state of the slivers at this AM. But the API is not clear what experimenters should expect, and does not provide easy ways for experimenters to control when and how states change. There is in particular no way to move slivers through states and change them in ways otherwise undefined by the API.
Change Set F3: Sliver Allocation States and methods
This change was discussed and adopted at the GEC13 Coding Sprint.
For meeting minutes, see: the GEC13 Coding Sprint agenda page.
- We agreed to use two kinds of states: allocation states, and operational states. We put off discussion of operational states (i.e. is the node booted), noting however that this is critical. See Change Set F4.
- We debated whether the API should specify a limited number of states, or allow for aggregate or resource specific states. We agreed that for allocation states, the API should define a limited set of states, while operational states might be more permissive.
- We discussed the pros and cons of including a single all-in-one method to change allocation states, or a single method per desired transition. There is at least 1 case where there are 2 paths between the same 2 allocation states with very different meaning. As a result, we agreed to use a separate method per allocation state change.
We agreed on 3 allocation states for slivers and an enumeration of methods for transitioning between those states.

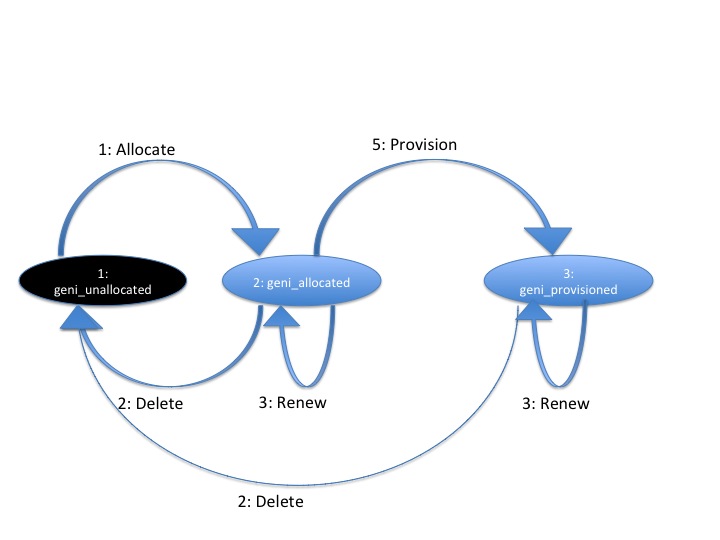
Allocation states:
geni_unallocated(alternatively called 'null'). The sliver does not exist. This is the small black circle in typical state diagrams.geni_allocated(alternatively called 'offered' or 'promised'). The sliver exists, defines particular resources, and is in a sliver. The aggregate has not (if possible) done any time consuming or expensive work to instantiate the resources, provision them, or make it difficult to revert the slice to the state prior to allocating this sliver. This state is what the aggregate is offering the experimenter.geni_provisioned. The aggregate has started instantiating resources, and otherwise making changes to resources and the slice to make the resources available to the experimenter. At this point, operational states are valid to specify further when the resources are available for experimenter use.
The key change is the addition of state 2, representing resources that have been allocated to a slice without provisioning the resources. This represents a cheap and reversible resource allocation, such as we previously discussed in the context of tickets. This compares reasonably well to the 'transaction' proposal written up by Gary Wong (http://www.protogeni.net/trac/protogeni/wiki/AM_API_proposals). When a sliver is created and moved into state 2 (geni_allocated), the aggregate produces a manifest RSpec identifying which resources are included in the sliver. This is something like the current CreateSliver, except that it does not provision nor start the resources. These resources are exclusively available to the containing sliver, but are not ready for use. In particular, allocating a sliver should be a cheap and quick operation, which the aggregate can readily undo without impacting the state of slivers which are fully provisioned. For some aggregates, transitioning to this state may be a no-op.
States 2 and 3 (geni_allocated and geni_provisioned) have aggregate and possibly resource specific timeouts. By convention the geni_allocated state timeout is typically short, like the redeem_before in ProtoGENI tickets, or the commit_by in Gary's transactions proposal. The geni_provisioned state timeout is the existing sliver expiration. If the client does not transition the sliver from geni_allocated to geni_provisioned before the end of the geni_allocated state timeout, the sliver reverts to geni_unallocated. If the experimenter needs more time, the experimenter should be allowed to request a renewal of either timeout. Note that typically the sliver expiration time (timeout for state 3, geni_provisioned) will be notably longer than the timeout for state 2, geni_allocated.
State 3, geni_provisioned, is the state of the sliver allocation after the aggregate begins to instantiate the sliver. Note that fully provisioning a sliver may take noticeable time. This state also includes a timeout - the sliver expiration time (which is not necessarily related to the time it takes to provision a resource). RenewSliver extends this timeout. For some aggregates and resource types, moving to this state from state 2 (geni_allocated) may be a no-op.
If the transition from one state to another fails, the sliver shall remain in its original state.
These are the only allocation states supported by this API. Since the state transitions are finite, but include potentially multiple transitions between the same two states, this API uses separate methods to perform each state transition, rather than a single method for requesting a new state for the sliver.
Allocatemoves 1+ slivers fromgeni_unallocated(state 1) togeni_allocated(state 2). This method can be described as creating an instance of the state machine for each sliver. If the aggregate cannot fully satisfy the request, the whole request fails. This is a change from the version 2 CreateSliver, which also provisioned the resources, and 'started' them. That isAllocatedoes 1 of the 3 things that CreateSliver did previously.Deletemoves 1+ slivers from either state 2 or 3 (geni_allocatedorgeni_provisioned), back to state 1 (geni_unallocated). This is similar to the AM API version 2 DeleteSliver.Renew, when given allocated slivers, requests an extended timeout for slivers in state 2 (geni_allocated).Renewcan also be used to request an extended timeout for slivers in state 3 - thegeni_provisionedstate. That is, this method's semantics can be the same as RenewSliver from AM API v2.Provisionmoves 1+ slivers from state 2 (geni_allocated) to state 3 (geni_provisioned). This is some of what version 2 CreateSliver did. Note however that this does not 'start' the resources, or otherwise change their operational state. This method only fully instantiates the resources in the slice. This may be a no-op for some aggregates or resources.
When Provision fails for only some slivers, and geni_best_effort option was supplied, the aggregate will return the status of each requested sliver individually. The geni_allocation_state for slivers that failed will remain geni_allocated. This typically suggests that the experimenter may retry the call. For some aggregates or resource types, the sliver may be 'dead', and Provision may never succeed. Experimenters should check geni_error for more information.
These states apply to each sliver individually. Logically, the state transition methods then take a single sliver URN. For convenience, these methods accept a list of sliver URNs, or a slice URN as a simple alias for all slivers in this slice at this aggregate.
Since each method may operate on multiple slivers, each of these methods returns a list of structs as the value:
value = [
{
geni_sliver_urn: <string>,
geni_allocation_status: <string>,
geni_expires: <time when the sliver expires from its current state>,
[optional: geni_error: string indicating why an operation failed on this sliver]
<others AM or method specific>
<Provision returns geni_operational_status>
},
...
]
Allocate returns a single manifest RSpec, plus the above list of structs.
Aggregates must be consistent across all these methods whether they are all or nothing, or support partial success.
These methods all take a new option (aggregates must support it, clients do not need to supply it):
geni_best_effort: <XML-RPC boolean 1/0, default 0>
If false, the client is requesting that the aggregate either fully satisfy the request, moving all listed slivers to the desired state, or fully fail the request, leaving all slivers in their original state. If the aggregate cannot guarantee all or nothing success or failure given the included slivers and resource types, the aggregate shall fail the request, returning an appropriate error code. If this option is true, then some slivers may transition to the new state, and some not. Experimenters must examine the return closely to know the state of their slivers.
Note: Allocate remains (like v2 CreateSliver) all or nothing (either the aggregate can allocate all desired resources as requested, or the call fails).
Note: These calls are synchronous - when they return, the slivers shall be in their final state. In particular, the transition from state 2 to 3 (geni_allocated to geni_provisioned) should be quick. The resource that is now in the 'provisioned' state may take a long time to actually be ready for operational use (e.g. imaging and booting the node) -- this remains true as in version 2 after CreateSliver. Note that the geni_allocated state is by definition cheap, such that transitioning to this state should also be quick.
SliverStatus, where it currently includes geni_status for each geni_resource, shall now return geni_allocation_status with one of the above defined values, and geni_operational_status. The values of geni_operational_status are still under discussion.
Currently, SliverStatus returns a single geni_status for the entire slice at this aggregate. With this change, the top-level allocation status for the slice is not defined, and that field is not required.
Open Questions:
- What about an UpdateAllocations method, similar to UpdateTickets or UpdateTransactions from other similar proposals, for modifying allocated resources in place, without losing allocated resources?
Change Set F4: Sliver Operations Method
This proposal was discussed on the geni-dev mailing list: http://lists.geni.net/pipermail/dev/2012-March/000743.html
The canonical source for documentation on this proposal is here: https://openflow.stanford.edu/display/FOAM/GENI+-+PerformOperationalAction
See Change Set F5 for a companion proposal for aggregates to advertise legal operational states and actions.
struct PerformOperationalAction (string urn[], struct credentials[], string action,
struct options={})
{
struct code = {
int geni_code;
[optional: string am_type;]
[optional: int am_code;]
}
struct value = [ {
'geni_sliver_urn' : <string>,
'geni_allocation_status' : <string>,
'geni_operational_status' : <string>,
'geni_expires': <dateTime.rfc3339 of individual sliver expiration>
[optional: 'geni_resource_status' : string]
}, ... ];
string output;
}
Performs the given action on the given sliver_urn(s) (or slice_urn as a proxy for "all slivers"). Actions are constrained to the set of default GENI actions, as well as resource-specific actions which reasonably perform operational resource tasks as defined by the aggregate manager for the given resource type. This method is not intended to allow for reconfiguration of options found in the request rspec. Aggregate Managers SHOULD return an error code of 13 (UNSUPPORTED) if they do not support a given action for a given resource. Actions are performed on all slivers, or none - if an action cannot be performed on a sliver given, the entire operation MUST fail. Passing the option geni_best_effort with a value of true allows for partial success (this option defaults to false if not supplied).
An AM SHOULD constrain actions based on the current operational state of the resource, such that for example attempting to perform the action geni_stop on a resource that is geni_ready_busy or geni_configuring or geni_stopping will fail, but SHOULD also be idempotent for all actions which result in a steady state.
geni_operational_status MUST be the current operational status of the sliver after this action (as would be returned by SliverStatus). An optional geni_resource_status field MAY be returned for each sliver which contains a resource-specific status that may be more nuanced than the options for geni_operational_status.
Calling this method with a slice_urn functions as if all the child sliver_urn's had been passed in - specifically the action is performed on all slivers and all sliver_urn's and their statuses are returned. No status is returned for the slice as a whole.
This is a fast synchronous operation, and MAY start long-running sliver transitions whose status can be queried using SliverStatus.
This method should only be called, and is only valid, when the sliver is fully allocated. In particular, given Change Set F5, this method is only applicable for slivers not in the geni_pending_allocation state.
Change Set F5: Sliver Operational States
Currently, geni_status in SliverStatus can have values configuring, ready, failed, unknown.
This proposal modifies that list, and renames those to use the standard 'geni_' prefix.
These states would be reported by various AM API methods, specifically SliverStatus, and would be used in reasoning about valid operations in PerformOperationalAction
The AM API defines a few operational states with particular semantics. AMs are not required to support them for a given set of resources, but if they use them, they must follow the given semantics. AMs are however STRONGLY encouraged to support them, to provide maximum utility. There is one state that AMs are required to support, geni_pending_allocation, for a sliver which has not been fully allocated and provisioned.
Similarly, the API defines a few operational actions: these need not be supported. AMs are encouraged to support these if possible, but only if they can be supported following the defined semantics.
AMs may have their own operational states/state-machine internally. AMs are required to advertise such states and actions that experimenters may see or use, by using Ad RSpec extensions. Operational states which the experimenter never sees, need not be advertised. Operational states and actions are generally by resource type. The standard RSpec extension attaches such definitions to the sliver_type element of RSpecs.
TODO: Jon Duerig will propose this extension, with examples covering PG/Emulab sliver_types.
Tools must use the operational states and actions advertisement to determine what operational actions to offer to experimenters, and what actions to perform for the experimenter. Tools may choose to offer actions which the tool does not understand, relying on the experimenter to understand the meaning of the new action.
States should be defined in terms of (a) whether the resource is accessible to the experimenter on the data or control planes, (b) whether an experimenter action is required to change from this state, and if so, (c) what action or actions are useful. If the resource will change states without explicit experimenter action, what is the expected next state on success.
Note that states represent the AM's view of the operational condition of the resource. This state represents what the AM has done or learned about the resource, but experimenter actions may cause failures that the AM does not know about.
Any operational action may fail. When this happens, the API method should return an error code. The sliver may remain in the original state. In some cases, the sliver may transition to the geni_failed state.
There is no busy state. Instead, AMs are encouraged to define separate such transition states for each separate transition path, allowing experimenters to distinguish the start and end states for this transition.
shutdown is not an operational state for a sliver. The Shutdown() API method applies to an entire slice.
Operational states are generally only valid for slivers which have been provisioned (geni_provisioned allocation state).
GENI defined operational states:
geni_pending_allocation: A wait state. The sliver is still being allocated and provisioned, and other operational states are not yet valid. PerformOperationalAction may not yet be called on this sliver. For example, the sliver is in allocation stategeni_provisioned, but has not been fully provisioned (e.g., the VM has not been fully imaged). Once the sliver has been fully allocated, the AM will transition the sliver to some other valid operational state, as specified by the advertised operational state machine. Common next states aregeni_notready,geni_ready, andgeni_failed.geni_notready: A final state. The resource is not usable / accessible by the experimenter, and requires explicit experimenter action before it is usable/accessible by the experimenter. For some resources,geni_startwill move the resource out of this state and towardsgeni_ready.geni_configuring: A wait state. The resource is in process of changing togeni_ready, and on success will do so without additional experimenter action. For example, the resource may be powering on.geni_stopping: A wait state. The resource is in process of changing togeni_notready, and on success will do so without additional experimenter action. For example, the resource may be powering off.geni_ready: A final state. The resource is usable/accessible by the experimenter, and ready for slice operations.geni_ready_busy: A wait state. The resource is performing some operational action, but remains accessible/usable by the experimenter. Upon completion of the action, the resource will return togeni_ready.geni_failed: A final state. Some operational action failed, rendering the resource unusable. An administrator action, undefined by this API, may be required to return the resource to another operational state.
GENI defined operational actions:
geni_start: This action results in the sliver becominggeni_readyeventually. The operation may fail (move togeni_failed), or move through some number of transition states. See EG booting a VM.geni_restart: This action results in the sliver becominggeni_readyeventually. The operation may fail (move togeni_failed), or move through some number of transition states. During this operation, the resource may or may not remain accessible. Dynamic state associated with this resource may be lost by performing this operation. See EG re-booting a VM.geni_stop: This action results in the sliver becominggeni_notreadyeventually. The operation may fail (move togeni_failed), or move through some number of transition states. See EG powering down a VM.
Actions are performed using the above proposed PerformOperationalAction.
Note that for some aggregates and resources, slivers may be automatically transitioned to geni_ready, without calling PerformOperationalAction. For others, the operation may be required by the state machine, but be implemented as a no-op.
Adopted: Change Set G: Credentials are general authorization tokens.
This change was adopted at GEC13.
Motivation
Most AM API methods take a list of credentials to authorize operations. Currently the API requires credentials in a particular format, and would disallow others, such as ABAC. The API should allow for other innovative authorization tokens.
Make credentials more general
This change modifies the credentials argument to all methods. Each credential is now defined only as a signed document. A given list of credentials may contain credentials in multiple formats. The list may be empty. A given authorization policy at an AM may require 0, 1, or many credentials. Aggregates are required to allow credentials which are not used by local authorization policy or engines, using only credentials locally relevant.
- An AM must pick credentials out of the list that it understands and be robust to receiving credentials it does not understand.
- Current slice and user credentials will be recognizable for following the schema defined in Change Set K.
- AMs are required to continue to accept current-format credentials.
- In particular, a single standard slice credential remains sufficient for most authorization policies.
- Other credential formats acceptable by some aggregates might include ABAC x509 Attribute certificates, eg.
- AMs may get other authorization material from other sources: EG a future Credential Store service.
Advertising supported credentials
We agreed that aggregates must advertise what types of credentials they accept so clients know how to gain authorization for API methods.
Aggregates are required to return a new entry in GetVersion:
geni_credential_types = <a list of structs>: [
{
geni_type: <string, case insensitive>,
geni_version: <string containing an integer>,
<others fields optionally. EG A URL for more info, or a schema>
}
]
We agreed that "sfa" slice credentials as defined pre AM API version 3 will have type=geni_sfa and version=2. "sfa" slice credentials as of AM API version 3 will be type=geni_sfa, version=3.
ABAC credentials as of AM API version 3 will be type=geni_abac, version=1.
For example, an aggregate that accepts ABAC credentials, SFA slice credentials that were issued prior to AM API v3, and SFA slice credentials from AM API version 3, would include this in GetVersion:
geni_credential_types = [
{
geni_type = "geni_sfa",
geni_version = "2"
},
{
geni_type="geni_sfa",
geni_version = "3"
},
{
geni_type="geni_abac",
geni_version="1"
}
]
Note that there might be multiple geni_type entries to support multiple versions of SFA credentials.
Note there might also be multiple kinds of ABAC credentials: identity certificates, attribute certificates, references to those certificates, bundles of those certificates. We briefly considered adding a sub_type field or a flag for 'credentials' that are really references to credentials.
Specifying Type of Supplied Credentials
For AMs to understand the type of each supplied credential, per-AM heuristics are not sufficient - they might differ at different AMs.
The API will require that credentials be explicitly typed. This change makes methods take in the credentials argument a struct:
credentials = [
{
geni_type: <string>,
geni_version: <string>,
geni_value: <string>,
<others>
}
]
Note that the value may be a credential, a URL, an XLink compliant string, etc. Clients are required to identify the type of each credential they supply. Instead of requiring clients to apply similar heuristics, authorities are required to identify credentials they supply with the same type and version fields. Specifically, ProtoGENI representatives suggested that their slice authorities would issue credentials as these structures in the near future.
Changes to existing methods
Modify a few existing methods to make certain operations easier or more experimenter friendly.
Change Set I: Misc other method changes
- Change Set I1: Add
geni_expiresto return from SliversStatus for whole slice and then each sliver- This change was adopted at GEC13
- This change standardizes behavior necessary for experimenters to determine their sliver expiration times.
- Format is RFC3339 (http://www.ietf.org/rfc/rfc3339.txt)
- Full date and time with explicit timezone: offset from UTC or in UTC)
- eg:
1985-04-12T23:20:50.52Zor1996-12-19T16:39:57-08:00
- Change Set I2: Add SSH logins/keys to each node that supports SSH login in the manifest RSpec
This change standardizes behavior so experimenters can readily find how to log in to reserved resources. Aggregates that allocate resources that an experimenter can 'log in to', should use this struct to return that information. Other aggregates will not use this at all.
- This change was adopted at GEC13.
Aggregates shall use a new RSpec extension to include all login information in manifest RSpecs. This extension is version controlled in the GENI RSpec git repository.
The extension adds information to the <services> tag, which already has the <login> tag.
The <login> tag tells you the kind of authentication (ssh), the port, and the username.
The new extension adds an entry per login username
- URN of the user
- 1+ public SSH keys that can be used under that login
Note that 1 of the <user:services_user login>s in the extension duplicates the default username already in the base <login> tag. The extension allows specifying the keys usable with that login username.
EG:
.......
<services>
<login authentication="ssh-keys" hostname="pc27.emulab.net" port="22" username="flooby"/>
<ssh-user:services_user login="flooby" user_urn="http://urn:publicid:IDN+jonlab.tbres.emulab.net+user+flooby">
<ssh-user:public_key>asdfasdfasdf;lkasdf=foo@bar</ssh-user:public_key>
<ssh-user:public_key>asdfasdfasdf;lkjasdf;lasdf=foobar@barfoo</ssh-user:public_key>
</ssh-user:services_user>
<ssh-user:services_user login="io" user_urn="http://urn:publicid:IDN+jonlab.tbres.emulab.net+user+io">
<ssh-user:public_key>asdfasdfasdf;lkasdf=foo@bar</ssh-user:public_key>
<ssh-user:public_key>asdfasdfasdf;lkjasdf;lasdf=foobar@barfoo</ssh-user:public_key>
</ssh-user:services_user>
</services>
And the RNC schema:
# An extension for describing user SSH login credentials in the manifest
default namespace = "http://www.protogeni.net/resources/rspec/ext/ssh_user/1"
# This is meant to extend the services element
Services = element services_user {
attribute login { string } &
attribute user_urn { string }? &
element public_key { string }*
}
# Both of the above are start elements.
start = Services
- A note on distinguishing ListResources from SliversStatus:
- ListResources in the context of a slice URN is for listing the reserved resources. It provides mostly static information. (But if the manifest contains things which can change, then the manifest must change when those things (like say IP addresses) change.)
- SliversStatus is for everything else: anything which the AM can change for you using API calls, or which changes over time. So it has up/down state, expiration time, and now login keys. It provides that for your whole slice at this aggregate and all contained slivers.
- Change Set I3: Return sliver expiration from CreateSlivers
- This change was adopted at GEC13.
Experimenters currently do not know the expiration of their slivers without explicitly asking. This change makes the CreateSlivers return value become a struct:
{
rspec: <string manifest>,
geni_expires: =<RFC3339 sliver expiration string, as in geni_expires from SliversStatus>,
geni_allocation_status: <string sliver state - allocated or changing or ready>,
<others that are AM specific>
}
Adopted: Change Set K: Standardize certificates and credentials
This proposal was adopted at GEC13
Motivation
The current AM API specifies that certificates and credentials follow a particular format, using URNs that are based on experimenter supplied names. However that specification is not sufficiently specific, and there are currently differences in implementation among existing certificate and credential producers. This has led to errors, experimenter confusion, and messy code.
Changes
This proposal requires that certificates include a UUID and email address for the subject. It codifies restrictions on usernames, sliver names, and slice names. The proposal specifies that slices have a UUID to be used to help identify slices in a consistent way over time (slice names may be re-used).
Some overall points:
- Aggregates are expected to fail requests that use certificates or URNs or names that violate this API.
- Schemas for certificates & credentials will be published on geni.net.
Certificates:
- GENI uses x509v3 identity certificates to identity users, slices, aggregates, and authorities, and these restrictions apply to all such certificates.
- See http://groups.geni.net/geni/wiki/GeniApiCertificates.
- Aggregates are required to properly validate all certificates to authenticate access to AM API calls, and fail calls that supply invalid certificates.
Certificate contents:
Versionshall be properly marked: 3serialNumis required to be unique within the certificate authority: each newly issued certificate must have a unique serial number.- The Distinguished Name should include a human readable identifier, for both subject and issuer. Details are not specified.
- Only authority certificates (but all authorities that issue certificates) shall be marked
CA:TRUEin the x509 v3 basic constraints; Slices and users shall be markedFALSE. - The Subject Alternative Name field must include 3 pieces of information
- Entries are comma separated ('
,'), and may be in any order. - The URN identifier, following GENI URN standards as described here: http://groups.geni.net/geni/wiki/GeniApiIdentifiers
- The URN is identifiable by looking for the entry beginning "
URI:urn:publicid:IDN", for example:URI:urn:publicid:IDN+emulab.net+user+stoller.
- The URN is identifiable by looking for the entry beginning "
- A UUID, providing a unique ID for the entity.
- The UUID must be used with the URN to fully identify the slice or user. UUID alone should not be accepted. This ensures that the authority certifying the slice or user is always identified when referring to the slice or user.
- In the hexadecimal digit string format given in RFC 4122
- The UUID is identified with this prefix: "
URI:urn:uuid" (as specified by RFC4122), for example:URI:urn:uuid:33178d77-a930-40b1-9469-3aae08755743. - The
COPYtag is not supported.
- The email address is an RFC2822 compliant and working address for contacting the subject of the certificate (experimenter, authority administrator, or slice owner).
- The email entry is identified by the prefix "
email:", for example:email:stoller@emulab.net - The
COPYtag is not supported. - Note that the slice and user email addresses are addresses for contacting the responsible party - the slice owner or creator and the user. These may be aliases.
- The email entry is identified by the prefix "
- Entries are comma separated ('
- Recommendation: Authorities are encouraged but not required to include a URL where more information about the subject is available (eg slice authority registry URL). That URL may be included in a certificate extension, in the DN, or in the subjectAltName.
Slices:
- Slice ID for use over time and space is the UUID plus the URN in the slice certificate.
- Currently URNs identify slices, but they are not unique over time. This change adds UUIDs to slice identifiers. URNs remain the identifier for slices in AM API calls, and uniquely identify slices for a moment in time. UUID plus URN together uniquely identify slices over time, and can be used for forensics, or for use by authorization modules, such as ABAC. UUIDs alone should not be used to identify slices, but only in conjunction with the URN, which scopes the UUID to the authority which generated the UUID. The UUID essentially may only be used to distinguish between slices with identical URNs.
- Monitoring and instrumentation interfaces will likely require both the URN and the UUID for recording slice measurements that can be used past the life of the slice, and aggregates must be prepared to provide both.
- Slice URN alone is a label - unique at a point in time but not over time.
- Format:
urn:publicid:IDN+<SA name>+slice+<slice name>
- Format:
- Slice names are <=19 characters, only alphanumeric plus hyphen (no hyphen in first character):
'^[a-zA-Z0-9][-a-zA-Z0-9]\{0,18\}$' - Aggregates are required to accept any compliant slice name and URN.
- Note that this currently causes problems at PlanetLab/SFA aggregates, where node login names are based on slice names and are limited to 31 characters.
Slivers:
- Have a URN (returned in manifest RSpec), determined by the aggregate.
- This URN should be unique over time within an AM for record-keeping / operations purposes.
- Format:
urn:publicid:IDN+<AM name>+sliver+<sliver name>
- Format:
- Sliver names
- Must be unique over time within that AM, and are selected by the AM.
- May use only alphanumeric characters plus hyphen.
Usernames:
- Usernames (user identifiers to the system) are set at the authority.
- Usernames are case-insensitive internally, though they may be case-sensitive in display.
- EG
JohnSmthas a display name isjohnsmthinternally, and there cannot also be a userJOHNSMTH.
- EG
- Usernames should begin with a letter and be alphanumeric or underscores - no hyphen or '.': (
'^[a-zA-Z][\w]\{1,8\}$'). - Usernames are limited to 8 characters.
- User URNs (which contain the authority name and the username) are required to be temporally and globally unique.
Change Set M: New Method Signatures
Given all the other adopted change set proposals, there will be new method signatures.
In some cases, the proposals are not clear in terms of the details of the resulting method signatures. This proposal consolidates those separate proposals, to propose a new set of method signatures.
There are a few other small changes that this change set covers.
The details of the proposed final method signatures are listed on the API version 3 page.
M1: users struct an option
Previously, the CreateSliver method took a users[] struct to specify information for logging in to resources. But this struct is not universally applicable. This change moves that struct to be an option within the options struct, named geni_users[]. All other semantics and syntax for this argument remain the same from AM API version 2.
M2: Split ListResources
Currently, ListResources has two forms: (1) get an advertisement general to the aggregate, and (2) get a manifest specific to a slice. This proposal splits those two modes into two separate methods, ListResources, and Describe.
ListResources would no longer take a slice_urn option, and no longer ever return a manifest RSpec.
Describe would be used to achieve that same functionality.
struct Describe(string urns[], struct credentials[], struct options[])
Where options include:
{
boolean geni_compressed <optional>;
struct geni_rspec_version {
string type;
string version;
};
}
Return struct:
{
geni_rspec: <geni.rspec, Manifest>
geni_urn: <string slice urn of the containing slice>
geni_slivers: [
{
geni_sliver_urn: <string sliver urn>
geni_expires: <dateTime.rfc3339 allocation expiration string, as in geni_expires from SliversStatus>,
geni_allocation_status: <string sliver state - allocated or ?? >,
geni_operational_status: <string sliver operational state>
},
...
]
}
Aggregates are expected to combine the manifests of all requested slivers into a single manifest RSpec. Note that a manifest returned here for only some of the slivers in a slice at this aggregate, may contain references to resources not described in this manifest (they are in other slivers). As a result, such manifests may not be directly usable as a subsequent request.
Attachments (1)
- sliver-alloc-states3.jpg (42.8 KB) - added by 12 years ago.
{kind=link}
Download all attachments as: .zip