
| Version 35 (modified by , 12 years ago) (diff) |
|---|
-
GENI Aggregate Manager API Version 3 Common Concepts
-
Common Arguments, Returns, and Concepts
- structs and optional arguments
- RSpec data type
-
credentials -
options - Operations on Individual Slivers
-
urns[] - Sliver Allocation States
- Sliver Operational States
- Sliver Operational Actions
- Return Struct
- datetime data type
-
geni_end_time - Expiration times
-
geni_best_effort -
geni_users - User login information - Manifest Rspec Extension
-
geni_error - Documenting Aggregate Additions
- Supporting Multiple API Versions
-
Common Arguments, Returns, and Concepts
GENI Aggregate Manager API Version 3 Common Concepts
This page documents the GENI Aggregate Manager API version 3 common concepts.
The current officially adopted version of the API is 3 and is documented on the main API page.
The change sets for the AM API, whose impacts are reflected here, are documented on the AM API Draft wiki page.
For a summary of the method signatures of the Aggregate Manager API version 3, see the main AM API v3 page.
Common Arguments, Returns, and Concepts
structs and optional arguments
Unless otherwise specified, all arguments and returns of type struct may include aggregate or resource-specific entries. As arguments, such options must be optional for the client to supply, with the aggregate providing a reasonable default.
RSpec data type
Throughout this API, multiple arguments and returns are labeled as an RSpec. These fields shall be understood as XML documents following one of the schemas advertised in the return from GetVersion. All such RSpecs must pass an XML schema validator, must list all used schemas and namespaces within the document, using schemas that are publicly available. The GetVersion return advertises schemas for advertisement and request RSpecs; the schemas for manifest RSpecs are assumed to be available at the same base URL, but using a corresponding manifest schema.
A fully GENI AM API compliant aggregate will always support the GENI standard schemas for RSpecs, available at http://www.geni.net/resources/rspec. As of 4/2012, the current GENI RSpec version is 3 (type is geni, case insensitive). Aggregates are free to use an alternate format internally, but must accept and produce compliant RSpecs on demand.
More information on GENI RSpecs is available on the ProtoGENI wiki.
The Aggregate Manager (AM) API requires this contract: Aggregates advertise the type and version of RSpec formats that they support. If available, they specify the schema, namespace and extensions combination which is the authoritative definition of that format. Clients of the API should understand that combination in order to know how to understand the resources available at that aggregate.
If an aggregate advertises a particular type/version (optionally defined with a combination of schema, namespace and extensions) in the geni_ad_rspec_versions attribute of GetVersion, then it promises to send a correct Advertisement RSpec in response to a ListResources call which supplies a geni_rspec_version option containing that type/version. (geni_rspec_version is a struct with 2 members, type and version. type and version are case-insensitive strings, matching those in geni_ad_rspec_versions).
If an Aggregate advertises a particular type/version (optionally defined with a combination of schema, namespace and extensions) in the geni_request_rspec_versions attribute of GetVersion then it promises to correctly honor an Allocate (was CreateSliver in API v2) call containing a request RSpec in the given format, and then to return a Manifest RSpec in the corresponding format (i.e. a GENI format request is answered with a GENI format manifest). The aggregate also promises to send a correctly formatted Manifest RSpec in response to a Describe call which supplies a valid slice URN or list of sliver URNs and an geni_rspec_version option containing that supported type/version.
In this API, such RSpec fields are labeled as type geni.rspec.
credentials
Many methods take an array of credentials to authorize the caller to perform the given operation with the given arguments. See the GENI AM API Credentials page. This array argument is actually an array of structures specifying the credential type and version, as well as the actual string credential.
credentials = [
{
geni_type: <string, case insensitive>,
geni_version: <string, case insensitive>,
geni_value: <string>,
<others>
}
]
Each credential (in geni_value) is defined as a signed document. A given list of credentials may contain credentials in multiple formats. The list may be empty. A given authorization policy at an AM may require 0, 1, or many credentials. Aggregates are required to allow credentials which are not used by local authorization policy or engines, using only credentials locally relevant.
- An AM must pick credentials out of the list that it understands and be robust to receiving credentials it does not understand.
- Aggregates can identify and use valid slice and user credentials by matching against the schema defined in GeniApiCredentials.
- AMs are required to continue to accept current-format credentials as specified in GeniApiCredentials.
- In particular, a single standard slice credential remains sufficient for most authorization policies.
- Other credential formats acceptable by some aggregates might include ABAC x509 Attribute certificates, eg.
- AMs may get other authorization material from other sources: EG a future Credential Store service.
At least one subset of the credentials (e.g. a single SFA style slice credential) must authorize operations for the slice specified in slice_urn if that is an argument, or for the slice that contains the named slivers, if sliver urns are an argument, or a valid set of administrative credentials with sufficient privileges. When sliver_urns are supplied, all such slivers must belong to the same slice, over which the given credential set provides access. Methods that do not take a slice urn or sliver urns, but do take credentials, are interpreted to require credentials that authorize the user generally. For example, an SFA style user credential must be supplied. Credentials must be valid (signed by a valid GENI certificate authority either directly or by chain, not expired, and grant privileges to the client identified by the SSL client certificate). Each method requires specific privileges, which must be granted by the provided credentials. Note that the semantics of this argument is not clear: most implementations require a single credential to provide all needed privileges. Alternative interpretations might, for example, accumulate privileges from each valid credential to determine overall caller permissions. For details on GENI AM API format credentials, see the GENI wiki.
Aggregates must advertise the type(s) of credentials they support, using a new entry in GetVersion:
geni_credential_types = <a list of structs>: [
{
geni_type: <string, case insensitive>,
geni_version: <string containing an integer>,
<others fields optionally. EG A URL for more info, or a schema>
}
]
"sfa" slice credentials as defined before AM API version 3 will have type=geni_sfa and version=2. "sfa" slice credentials as of AM API version 3 will be type=geni_sfa, version=3.
ABAC credentials as of AM API version 3 will be type=geni_abac, version=1.
For example, an aggregate that accepts ABAC credentials, SFA slice credentials that were issued prior to AM API v3, and SFA slice credentials from AM API version 3, would include this in GetVersion:
geni_credential_types = [
{
geni_type = "geni_sfa",
geni_version = "2"
},
{
geni_type="geni_sfa",
geni_version = "3"
},
{
geni_type="geni_abac",
geni_version="1"
}
]
options
An XML-RPC struct. For GetVersion only, this argument is optional. In all other methods, it is required. Only ListResources and Describe have required entries in the options struct. Aggregates are compliant with this API by accepting this argument. Aggregates may accept entries to this struct. Aggregates should not require any new options to any method - they should always have a reasonable default for any such option. Aggregates should document new options arguments. The prefix geni_ is reserved for members that are part of this API specification. Implementations should choose an appropriate prefix to avoid conflicts.
Operations on Individual Slivers
A Sliver is an aggregate defined grouping of resources within a slice at this aggregate, whose URN identifies the sliver, and can be used as an argument to methods such as Delete or Renew, and whose status can be independently reported in the return from Status. The AM defines 1 or more of these groupings to satisfy a given resource request for a slice. All reserved resources are directly contained by exactly 1 such sliver container, which is in precisely 1 slice.
One or more slivers are created by an aggregate when the experimenter tool calls Allocate(). This API encourages aggregates to independently manage each sliver, allowing experimenters to selectively Delete, Renew, or Provision each sliver. As such, these methods take a list of sliver urns (or a slice urn), and return a struct reporting results for each sliver URN independently. However, slivers at an aggregate may have interdependencies, and an individual aggregate may not be able to independently manage each sliver, without also modifying other related slivers. This API defines a number of aggregate configuration options returned by GetVersion, and an option to many methods, allowing aggregates to advertise their behavior, and experimenters to request particular behavior.
geni_single_allocation: <XML-RPC boolean 1/0, default 0>: When true (not default), and performing one of (Describe,Allocate,Renew,Provision,Delete), such an AM requires you to include either the slice urn or the urn of all the slivers in the same state. If you attempt to run one of those operations on just some slivers in a given state, such an AM will return an error.
For example, at an AM where geni_single_allocation is true you must Provision all geni_allocated slivers at once. If you supply a list of sliver URNs to Provision that is only 'some' of the geni_allocated slivers for this slice at this AM, then the AM will return an error. Similarly, such an aggregate would return an error from Describe if you request a set of sliver URNs that is only some of the geni_provisioned slivers.
geni_allocate: A case insensitive string, one of fixed set of possible values. Default isgeni_single. This option defines whether this AM allows adding slivers to slices at an AM (i.e. callingAllocate()multiple times, without first deleting the allocated slivers). Possible values:geni_single: Performing multipleAllocates without a delete is an error condition because the aggregate only supports a single sliver per slice or does not allow incrementally adding new slivers. This is the AM API v2 behavior.geni_disjoint: Additional calls toAllocatemust be disjoint from slivers allocated with previous calls (no references or dependencies on existing slivers). The topologies must be disjoint in that there can be no connection or other reference from one topology to the other.geni_many: Multiple slivers can exist and be incrementally added, including those which connect or overlap in some way. New aggregates should strive for this capability.
Many methods also take a new option (aggregates must support it, clients do not need to supply it):
geni_best_effort: <XML-RPC boolean 1/0, default 0>
If false, the client is requesting that the aggregate either fully satisfy the request, moving all listed slivers to the desired state, or fully fail the request, leaving all slivers in their original state. If the aggregate cannot guarantee all or nothing success or failure given the included slivers and resource types, the aggregate shall fail the request, returning an appropriate error code (UNSUPPORTED). If this option is true, then some slivers may transition to the new state, and some not. Experimenters must examine the return closely to know the state of their slivers - such methods will return data about all requested slivers. Aggregates may optionally return geni_error for each sliver for which the operation failed, to indicate further details. Note that Allocate is always all-or-nothing.
It is expected that many aggregates will implement one of the following combinations of options:
- Accept requests for
geni_best_effort= true, and advertisegeni_allocate=geni_many,geni_single_allocation= false (E.G. FOAM, PlanetLab). - Operate as though all requests were
geni_best_effort= false, and advertisegeni_allocate=geni_disjoint,geni_single_allocation= true (E.G. ProtoGENI).
urns[]
Several methods take some URNs to identify what to operate on. These methods are defined as accepting a list of arbitrary strings called URNs, which follow the GENI identifier rules. This API defines two kinds of URNs that may be supplied here, slice URNs and sliver URNs (see the GENI identifiers page). Some aggregates may understand other URNs, but these are not defined or required here. Aggregates that accept only URNs defined by this API will return an error when given URNs not in one of those forms. This API requires that aggregates accept either a single slice URN, or 1 or more sliver URNs that all belong to the same slice. Aggregates are not required to accept both a slice URN and sliver URNs, 2 or more slice URNs, or a set of sliver URNs that crosses multiple slices. Some aggregates may choose to accept other such combinations of URNs. Aggregates that accept only arguments defined by this API will return an error when given more than 1 slice URN, a combination of both slice and sliver URNs, or a set of sliver URNs that belong to more than 1 slice.
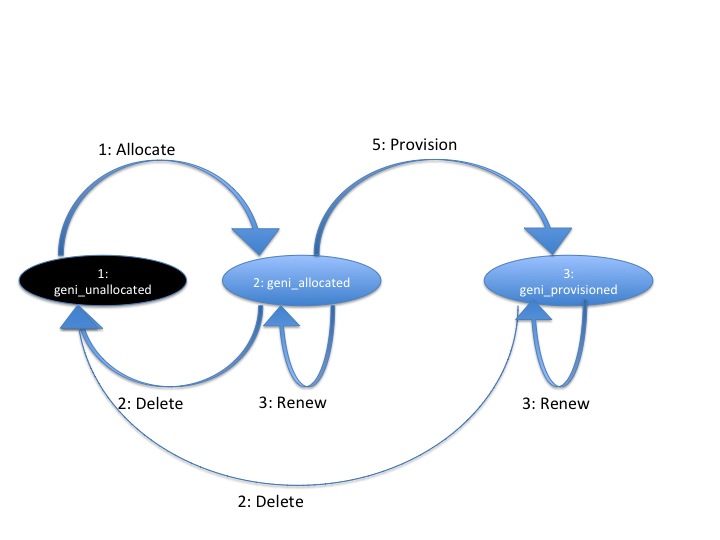
Sliver Allocation States
Many operations in this API create slivers or change the allocation status of slivers, and often return the current allocation status of each sliver.
Valid sliver allocation states are:
geni_unallocated(alternatively called 'null'). The sliver does not exist. This is the small black circle in typical state diagrams.geni_allocated(alternatively called 'offered' or 'promised'). The sliver exists, defines particular resources, and is in a sliver. The aggregate has not (if possible) done any time consuming or expensive work to instantiate the resources, provision them, or make it difficult to revert the slice to the state prior to allocating this sliver. This state is what the aggregate is offering the experimenter.geni_provisioned. The aggregate has started instantiating resources, and otherwise making changes to resources and the slice to make the resources available to the experimenter. At this point, operational states are valid to specify further when the resources are available for experimenter use.

Figure: Sliver Allocation States and AM API Method Transitions
geni_allocated represents resources that have been allocated to a slice without provisioning the resources. This represents a cheap and reversible resource allocation. When a sliver is created and moved into state 2 (geni_allocated), the aggregate produces a manifest RSpec identifying which resources are included in the sliver. These resources are exclusively available to the containing sliver, but are not ready for use. In particular, allocating a sliver should be a cheap and quick operation, which the aggregate can readily undo without impacting the state of slivers which are fully provisioned. For some aggregates, transitioning to this state may be a no-op.
States 2 and 3 (geni_allocated and geni_provisioned) have aggregate and possibly resource specific timeouts. By convention the geni_allocated state timeout is typically short, to keep most resources available. The geni_provisioned state timeout is the sliver expiration. If the client does not transition the sliver from geni_allocated to geni_provisioned before the end of the geni_allocated state timeout, the sliver reverts to geni_unallocated. If the experimenter needs more time, the experimenter should be allowed to request a renewal of either timeout. Note that typically the sliver expiration time (timeout for state 3, geni_provisioned) will be notably longer than the timeout for state 2, geni_allocated.
State 3, geni_provisioned, is the state of the sliver allocation after the aggregate begins to instantiate the sliver. Note that fully provisioning a sliver may take noticeable time. This state also includes a timeout - the sliver expiration time (which is not necessarily related to the time it takes to provision a resource). Renew extends this timeout. For some aggregates and resource types, moving to this state from state 2 (geni_allocated) may be a no-op.
If the transition from one state to another fails, the sliver shall remain in its original state.
Several AM API methods can be described in terms of transitions among allocation states.
Allocatemoves 1 or more slivers fromgeni_unallocated(state 1) togeni_allocated(state 2). This method can be described as creating an instance of the state machine for each sliver. If the aggregate cannot fully satisfy the request, the whole request fails. This is a change from the AM API V2CreateSliver, which also provisioned the resources, and 'started' them. That isAllocatedoes one of the three things thatCreateSliverdid previously.Deletemoves 1 or more slivers from either state 2 or 3 (geni_allocatedorgeni_provisioned), back to state 1 (geni_unallocated). This is similar to the AM API AM API V2DeleteSliver.Renew, when given allocated slivers, requests an extended timeout for slivers in state 2 (geni_allocated).Renewcan also be used to request an extended timeout for slivers in state 3 (thegeni_provisionedstate). That is, this method's semantics can be the same asRenewSliverfrom AM API v2.Provisionmoves 1 or more slivers from state 2 (geni_allocated) to state 3 (geni_provisioned). This is some of what AM API V2CreateSliverdid. Note however that this does not 'start' the resources, or otherwise change their operational state. This method only fully instantiates the resources in the slice. This may be a no-op for some aggregates or resources.
When Provision fails for only some slivers, and geni_best_effort option was supplied, the aggregate will return the status of each requested sliver individually. The geni_allocation_state for slivers that failed will remain geni_allocated. This typically suggests that the experimenter may retry the call. For some aggregates or resource types, the sliver may be 'dead', and Provision may never succeed. Experimenters should check geni_error for more information.
These states apply to each sliver individually. Logically, the state transition methods then take a single sliver URN. For convenience, these methods accept a list of sliver URNs, or a slice URN as a simple alias for all slivers in this slice at this aggregate.
Sliver Operational States
Slivers, once fully allocated, are said to be in a particular operational state. States may indicate that a sliver is configuring, running, ready, turning, etc. These states are used by tools to know what sliver-internal actions are relevant, and what aggregate-defined operational actions may be valid.
The AM API defines a few operational states with particular semantics. AMs are not required to support the API defined states for all resources, but if the aggregate uses the API defined states, then the aggregate must follow the given semantics. AMs are however STRONGLY encouraged to support them, to provide maximum interoperability. There is one state that AMs are required to support, geni_pending_allocation, for a sliver which has not been fully allocated and provisioned (other operational states are not yet valid). Operational states are generally only valid for slivers which have been provisioned (geni_provisioned allocation state).
AMs may have their own operational states/state-machine internally. AMs are however required to advertise such states and actions that experimenters may see or use, by using an advertisement RSpec extension (if an AM does not advertise operational states, then tools can not know whether any actions are available). Operational states which the experimenter never sees, need not be advertised. Operational states and actions are generally by resource type. The standard RSpec extension attaches such definitions to the sliver_type element of RSpecs.
The standard advertisement RSpec extension for advertising operational states and actions can be found here, with an example with comments here (it is version-controlled in the standard GENI RSpecs git repository as well).
States should be defined in terms of
- whether the resource is accessible to the experimenter (on either the data or control planes),
- whether an experimenter action is required to change from this state, and if so,
- what action or actions are useful. If the resource will change states without explicit experimenter action, what is the expected next state on success.
Note that states represent the AM's view of the operational condition of the resource. Each state represents what the AM has done or learned about the resource, but experimenter actions may cause failures that the AM does not know about. For example, the AM may advertise a state of geni_ready for a machine when the experimenter has manually rebooted the machine.
There is no generic busy state. Instead, AMs are encouraged to define separate similar transition states for each separate transition path, allowing experimenters to distinguish the start and end states for this transition.
Shutdown is not an operational state for a sliver. The Shutdown() API method applies to an entire slice.
States are generally of one of two forms:
- 'wait' states: The AM will change the sliver, causing its operational state to change, without experimenter action.
- 'final' states: The sliver will remain in this state, until and unless the experimenter invokes an operational action on the sliver.
Some AMs may allow actions during 'wait' states, (e.g. 'Cancel').
Operational actions immediately change the sliver operational state (if any change will occur). Long running actions therefore require a 'wait' state, while the action is completing.
GENI defined operational states (both required and optional for aggregates):
geni_pending_allocation: Required for aggregates to support. A wait state. The sliver is still being allocated and provisioned, and other operational states are not yet valid.PerformOperationalActionmay not yet be called on this sliver. For example, the sliver is in allocation stategeni_provisioned, but has not been fully provisioned (e.g., the VM has not been fully imaged). Once the sliver has been fully allocated, the AM will transition the sliver to some other valid operational state, as specified by the advertised operational state machine. This state is generally not part of the AM's advertised state machine, as it represents 'operational states not valid yet'. Common next states (and first states of operational state machines) aregeni_notready,geni_ready, andgeni_failed.geni_notready: A final state. The resource is not usable / accessible by the experimenter, and requires explicit experimenter action before it is usable/accessible by the experimenter. For some resources,geni_startwill move the resource out of this state and towardsgeni_ready.geni_configuring: A wait state. The resource is in process of changing togeni_ready, and on success will do so without additional experimenter action. For example, the resource may be powering on.geni_stopping: A wait state. The resource is in process of changing togeni_notready, and on success will do so without additional experimenter action. For example, the resource may be powering off.geni_ready: A final state. The resource is usable/accessible by the experimenter, and ready for slice operations.geni_ready_busy: A wait state. The resource is performing some operational action, but remains accessible/usable by the experimenter. Upon completion of the action, the resource will return togeni_ready.geni_failed: A final state. Some operational action failed, rendering the resource unusable. An administrator action, undefined by this API, may be required to return the resource to another operational state.
Sliver Operational Actions
Operational actions are commands that the aggregate exposes, allowing an experimenter tool to modify or act on a sliver from outside of the sliver (i.e. without logging in to a machine), without modifying the sliver reservation. Actions may cause changes to sliver operational state.
The API defines a few operational actions: these need not be supported. AMs are encouraged to support these if possible, but only if they can be supported following the defined semantics.
AMs may have their own operational states/state-machine internally. AMs are however required to advertise such states and actions that experimenters may see or use, by using an advertisement RSpec extension (if an AM does not advertise operational states, then tools can not know whether any actions are available). Operational states which the experimenter never sees, need not be advertised. Operational states and actions are generally by resource type. The standard RSpec extension attaches such definitions to the sliver_type element of RSpecs.
The standard advertisement RSpec extension for advertising operational states and actions can be found here, with an example with comments here.
Tools must use the operational states and actions advertisement to determine what operational actions to offer to experimenters, and what actions to perform for the experimenter. Tools may choose to offer actions which the tool itself does not understand, relying on the experimenter to understand the meaning of the new action.
Any operational action may fail. When this happens, the API method should return an error code. The sliver may remain in the original state. In some cases, the sliver may transition to the geni_failed state.
Operational actions immediately change the sliver operational state (if any change will occur). Long running actions therefore require a 'wait' state, while the action is completing.
GENI defined operational actions:
geni_start: This action results in the sliver becominggeni_readyeventually. The operation may fail (move togeni_failed), or move through some number of transition states. For example, booting a VM.geni_restart: This action results in the sliver becominggeni_readyeventually. The operation may fail (move togeni_failed), or move through some number of transition states. During this operation, the resource may or may not remain accessible. Dynamic state associated with this resource may be lost by performing this operation. For example, re-booting a VM.geni_stop: This action results in the sliver becominggeni_notreadyeventually. The operation may fail (move togeni_failed), or move through some number of transition states. For example, powering down a VM.
Return Struct
AM API methods return a struct, with at least three members. code, value, and output together provide the standard return from all AM API methods.
code-
A struct indicating the success or failure of this call at the Aggregate Manager. It consists of 1 required field and 2 optional fields.
struct code = { int geni_code; [optional: string am_type;] [optional: int am_code;] }
value- Method-specific. Required on success. Optional on error.
output- On failure or error, this is required. Optional on success. This is an XML-RPC string with a human readable message explaining the result. Specifically, this might include an error string, a stacktrace, or other useful messages to help the experimenter resolve or report the failure or error. It is not defined on success, though aggregates are free to use it.
Implementations can add additional members to the return struct as desired. The prefix geni_ is reserved for members that are part of this API specification. Implementations should choose an appropriate prefix to avoid conflicts. Aggregates should document any additional return values.
Aggregates shall return consistent values for geni_code as described here. Aggregates wishing to be more specific may use the am_type and am_code values.
Success is always indicated using a geni_code value of 0.
On one of the error or failure cases listed in the table below, aggregates shall return the indicated error code.
Elements in code
geni_code-
An integer supplying the GENI standard return code indicating the success or failure of this call. Error codes are standardized and defined in the attached XML document. Codes may be negative. A success return is defined as
geni_codeof0.
am_type-
Optional. A (case insensitive) string indicating the type of Aggregate Manager running locally. For example,
orca. When an aggregate wants to return an aggregate specific return code in theam_codefield, they supply anam_typeto qualify the kind of aggregate specific return code they are supplying. This is the namespace of the aggregate specific return code. This field is optional: aggregates are not required to supply an aggregate specific return code, and clients need not look at it. This code further qualifies the kind of error or success that the aggregate is returning, as primarily defined by the value ofgeni_code. Standard values foram_typeare defined in the attached XML document. am_code-
An integer supplying the more specific return code, relative to the aggregate type specified in
am_type. This integer may be negative. Aggregates should document these codes publicly. This API does not specify how or where that documentation should be provided.
Aggregates are encouraged to use code values and output messages that help experimenters and tools distinguish between bad input, other experimenter error, temporary server errors, or server bugs.
GENI standard error codes are documented in the attached XML document, and listed below.
| 0 | SUCCESS | "Success" |
| 1 | BADARGS | "Bad Arguments: malformed arguments" |
| 2 | ERROR | "Error (other)" |
| 3 | FORBIDDEN | "Operation Forbidden: eg supplied credentials do not provide sufficient privileges (on given slice)" |
| 4 | BADVERSION | "Bad Version (eg of RSpec)" |
| 5 | SERVERERROR | "Server Error" |
| 6 | TOOBIG | "Too Big (eg request RSpec)" |
| 7 | REFUSED | "Operation Refused" |
| 8 | TIMEDOUT | "Operation Timed Out" |
| 9 | DBERROR | "Database Error" |
| 10 | RPCERROR | "RPC Error" |
| 11 | UNAVAILABLE | "Unavailable (eg server in lockdown)" |
| 12 | SEARCHFAILED | "Search Failed (eg for slice)" |
| 13 | UNSUPPORTED | "Operation Unsupported" |
| 14 | BUSY | "Busy (resource, slice); try again later" |
| 15 | EXPIRED | "Expired (eg slice)" |
| 16 | INPROGRESS | "In Progress" |
| 17 | ALREADYEXISTS | "Already Exists (eg the slice}" |
Aggregates are similarly encouraged to provide hints on how to fix bad requests using the value entry to experimenters on error or failures. For example, a failed Renew call that failed because you are not allowed to renew your sliver that far in the future, might return a new date string in the value field that would be allowed. Similarly, a failed Allocate call might return a modified request RSpec in the value field.
Note that a malformed XML-RPC request should still raise an XML-RPC Fault, and other Faults dictated by the XML-RPC specification should still be raised. Aggregates should avoid raising an error (XML-RPC Fault) for application layer errors or any other cases where the XML-RPC specification does not require a Fault, but rather should attempt to return this struct, providing any error messages and stack traces in the output field or other additional fields. Certain XML-RPC errors may be returned using Faults or otherwise by the XML-RPC layer, or may more properly be returned using this struct in the application layer. In such cases, servers should use error codes with negative values. Selected such errors are listed below:
| -32001 | SERVERBUSY | "Server is (temporarily) too busy; try again later" |
Note also that servers may respond with other HTTP error codes, and clients must be prepared to deal with those situations. Specifically, a server that is busy might return HTTP code 503, or just refuse the connection.
datetime data type
All datetime arguments and returns in this API shall conform to RFC 3339. This represents a subset of the valid date/time strings permissible by the standard XML-RPC date/time data type, dateTime.iso8601.
- Full date and time with explicit timezone: offset from UTC or in UTC)
- e.g.: 1985-04-12T23:20:50.52Z or 1996-12-19T16:39:57-08:00
In the specification of this API, this is described as dateTime.rfc3339.
geni_end_time
The geni_end_time argument requests an expiration of the specified slivers. It is in dateTime.!rfc3339 format (defined above).
When an explicit argument, it is required, and aggregates must honor the request to the extent local policy permits.
When an option in the options struct, clients may omit the option, and AMs may choose not to or be unable to honor this option, but may still succeed the overall request.
Expiration times
Slivers have expiration times. Expiration times are set by local aggregate policy. Generally
geni_allocatedsliver expiration times are short (minutes)geni_provisionedsliver expiration times are longer (days)- All expiration times are limited by the expiration time of presented certificates and credentials
When a sliver expires, the aggregate deletes the sliver automatically. This includes stopping resources and freeing the reservation.
geni_best_effort
geni_best_effort: <XML-RPC boolean 1 or 0, default false (0)>
Clients may omit this option, but aggregates must honor the option if possible. This option modifies the way that the operation applies to all named slivers. By default (geni_best_effort=false), the operation must apply equally to all slivers, either succeeding or failing for all. When true, the aggregate may succeed the operation for some slivers, while failing the operation for other slivers.
This option applies to Provision, Renew, Delete, and PerformOperationalAction. Each of these methods returns a set of statuses for each requested sliver, allowing the AM to report individual results per sliver. This option does not apply to Allocate, which is always all or nothing.
geni_users
struct geni_users[] is an option for some methods.
Clients may omit this option. Aggregates should honor this option for any resource that accepts the provided login keys, and ignore it for other resources. This option is an array of user structs, which contain information about the users that might login to the sliver that the AM needs to know about. For example, this option is the mechanism by which users supply their SSH public keys, permitting SSH login to allocated nodes. In such cases, the corresponding manifest RSpec will contain the ssh-users element on each such node, showing the login username and applicable public keys. When this option is supplied, each struct must include the key keys, which is an array of strings and can be empty. The struct must also include the key urn, which is the user’s URN string. For example:
[
{
urn: urn:publicid:IDN+geni.net:gcf+user+alice
keys: [<ssh key>, <ssh key>]
},
{
urn: urn:publicid:IDN+geni.net:gcf+user+bob
keys: [<ssh key>]
}
]
User login information - Manifest Rspec Extension
Many GENI reservable resources allow experimenters to log in to the resource to control it. Aggregates shall use a new RSpec extension to include all login information in manifest RSpecs. This extension is version controlled in the GENI RSpec git repository.
The extension adds information to the <services> tag, which already has the <login> tag.
The <login> tag tells you the kind of authentication (ssh), the port, and the username.
The new extension adds an entry per login username
- URN of the user
- 1 or more public SSH keys that can be used under that login
Note that one of the <user:services_user login>s in the extension duplicates the default username already in the base <login> tag. The extension allows specifying the keys usable with that login username.
EG:
.......
<services>
<login authentication="ssh-keys" hostname="pc27.emulab.net" port="22" username="flooby"/>
<ssh-user:services_user login="flooby" user_urn="http://urn:publicid:IDN+jonlab.tbres.emulab.net+user+flooby">
<ssh-user:public_key>asdfasdfasdf;lkasdf=foo@bar</ssh-user:public_key>
<ssh-user:public_key>asdfasdfasdf;lkjasdf;lasdf=foobar@barfoo</ssh-user:public_key>
</ssh-user:services_user>
<ssh-user:services_user login="io" user_urn="http://urn:publicid:IDN+jonlab.tbres.emulab.net+user+io">
<ssh-user:public_key>asdfasdfasdf;lkasdf=foo@bar</ssh-user:public_key>
<ssh-user:public_key>asdfasdfasdf;lkjasdf;lasdf=foobar@barfoo</ssh-user:public_key>
</ssh-user:services_user>
</services>
And the RNC schema:
# An extension for describing user login credentials in the manifest
default namespace = "http://www.geni.net/resources/rspec/ext/user/1"
# This is meant to extend the services element
Services = element services_user {
attribute login { string } &
attribute user_urn { string }? &
element public_key { string }*
}
# Both of the above are start elements.
start = Services
geni_error
A free form string, optionally returned per sliver from several method returns (
Describe,Provision,Renew,Status,PerformOperationalAction,Delete). The aggregate manager should set this to a string that could be presented to a researcher to give more detailed information about the state of the sliver if this operation fails for a given sliver. This option is used in particular where an aggregate may successfully perform the operation for some slivers, but not others. See thegeni_best_effortoption above. In particular, it is not returned fromAllocate, which is always all-or-nothing. Note that this field may be omitted from the return in most cases, but is required in the return fromStatus, though it may be empty.
Documenting Aggregate Additions
Aggregates are free to add additional return values or input options to support aggregate or resource specific functionality, or to innovate within the bounds of the AM API. This includes adding new methods that use the same transport, interface, certificates, and credentials. Aggregates are encouraged to document any such new return values which they return or options arguments, to bootstrap coordination with clients, and provide documentation for human experimenters. One way to provide partial documentation, is to implement XML-RPC introspection. Through the use of method help, aggregates can provide human readable text describing return values. Alternatively or additionally, aggregates may document return values as part of their return from GetVersion. This API does not specify the format for advertising those extra return values in GetVersion.
Supporting Multiple API Versions
Aggregates are free to support multiple versions of the AM API. They do so by providing different URLs for each version of the API that they support. Aggregates should have a 'default' URL (the one typically advertised). That url runs whichever version of the API the server chooses (could be the latest, could be something else.)
When aggregates start supporting a new version of the API, they should keep running the old version of the API for a suitable transition period.
Aggregates running multiple versions of the API must advertise the URLs and versions of the API supported using the new GetVersion return as part of the value entry:
geni_api_versions: an XML-RPC struct containing 1 or more entries of: Name: Integer - supported GENI AM API version Value: String - URL to the XML-RPC server implementing that version of the GENI AM API
For example
geni_api_versions: {
1: <URL>,
2: <Local URL, as this is API version 2>,
...
}
The entries indicate versions of the API that are supported, and URLs are absolute URLs where that version of the API is supported.
Attachments (3)
- sliver-alloc-states3.jpg (42.8 KB) - added by 12 years ago.
- geni-error-codes.xml (7.4 KB) - added by 10 years ago.
- geni-am-types.xml (1.6 KB) - added by 10 years ago.
{kind=link}
Download all attachments as: .zip